How Einstein Copilot Search Uses Retrieval Augmented Generation to Make AI More Trusted and Relevant

At World Tour NYC, Salesforce introduced new unstructured data capabilities for Data Cloud and Einstein Copilot Search. By bringing together data retrieval capabilities using semantic search and prompts in Einstein Copilot, responses by Large Language Models (LLMs) will be more accurate, up-to-date, and generated with more transparency — while also keeping company data safe and secure through the Einstein Trust Layer.
These powerful new features are underpinned by an AI framework called Retrieval Augmented Generation (RAG), which enables companies to use their structured and unstructured proprietary data to make generative AI more trusted and relevant.
What is RAG?
Put simply, RAG helps companies retrieve and use their data, no matter where it lives, for better AI results. The RAG pattern coordinates queries and responses between a search engine and an LLM, and importantly, can operate on unstructured data such as emails, call transcripts, knowledge articles, and other formats that don’t fit cleanly into a typical relational data source. RAG can be more specifically described using its name:
- Retrieval: To steer LLMs toward more useful and trusted outputs, companies need to retrieve the most relevant data for use in the prompts they construct. A common technique for this is semantic search, which is core to Salesforce’s recently announced Einstein Copilot Search. Semantic search takes in a user’s request or question, and performs search based on its meaning or intent, not just based on the individual keywords within it.
- Augmented: With RAG, the LLM doesn’t need to be trained up front on this useful data. Instead, the relevant contextual data is simply given to the LLM, by automatically augmenting the prompt itself with the relevant contextual data.
- Generation: Finally, the augmented prompt is sent to the LLM, where it is used to generate an output, such as an outreach email or customer service reply. With RAG, this should be a response that the user can trust and that is using the most appropriate and recent data. And to help build confidence in the response, many implementations of the RAG pattern, such as the one Salesforce provides, will give users access to the AI model’s sources, ensuring that the output can be checked for accuracy.
How does RAG work?
RAG is a concept used broadly, but at Salesforce, it works in a specific and powerful way to make AI more trusted and relevant.
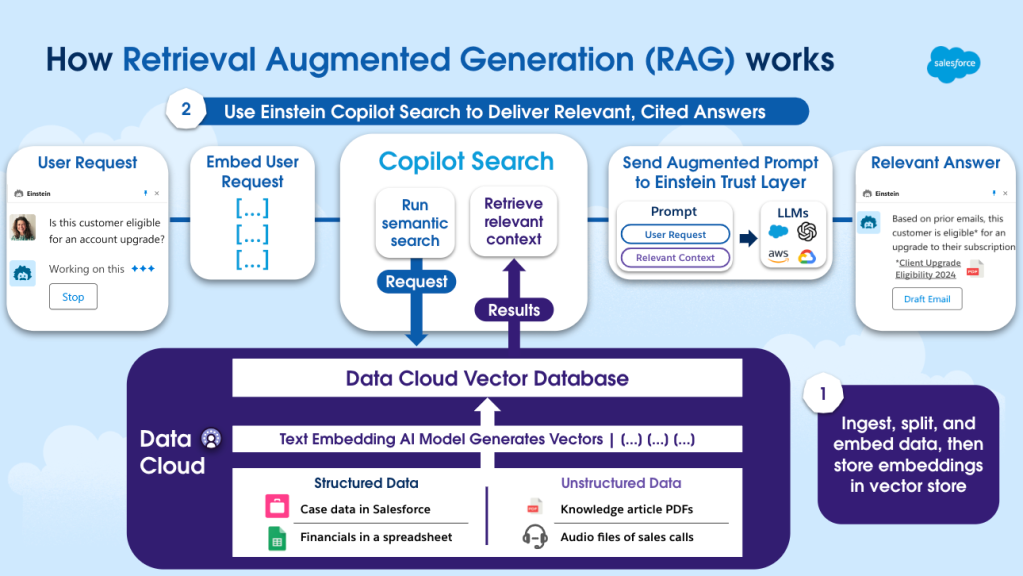
RAG begins with Salesforce Data Cloud. This hyperscale data platform is built into Salesforce, helping customers harmonize and unify their data so it can be activated across Salesforce applications.
- Data Cloud is now expanding to support storage of unstructured data such as PDFs, call transcripts, emails, and other binary objects. Given an estimated 90% of enterprise data exists in unstructured formats like PDFs, emails, social media posts, and audio files, making it accessible for business applications and AI models will greatly improve the quality of AI-generated output.
- A new unstructured data pipeline in Data Cloud enables teams to select the unstructured data they want to bring in – such as help articles sitting in a knowledge management service, or call transcripts in an S3 bucket – and make those usable across the Einstein 1 Platform. When ingesting text documents, that data can be chunked into smaller fragments to ensure more precise operations against that data. And to make this usable in operations like semantic search, it can then be transformed and stored in the new Data Cloud Vector Database.
- The Data Cloud Vector Database combines structured and unstructured data seamlessly and transforms it into a numerical representation called a vector embedding. This works by calling a special type of LLM called an embedding model through the Einstein Trust Layer. This vector embedding format makes it easier for an AI system to process the data, compare it against queries, and respond with a useful answer. Customers will only need to define which parts of their data should be searchable by using clicks to create a search index.
RAG powers meaningful response generation with Einstein Copilot Search: RAG in Salesforce also uses the newly announced Einstein Copilot Search, which will use the Data Cloud Vector Database to combine semantic search with traditional keyword search.
- When a user request comes in, like a question from a customer or an ask from an employee, the request is transformed into a vector embedding using the same embedding model used to embed unstructured data.
- Einstein Copilot Search then takes the numeric representation of the user input and runs a semantic search operation that compares it against unstructured data in the Data Cloud Vector Database. Because the request and the data to search against are in the same numeric format, users can employ powerful AI algorithms such as “k-nearest neighbors” to find the structured or unstructured content that is most semantically similar to the user’s question.
- To ensure these outputs are as relevant as possible, semantic search technique is combined with keyword search to further refine results. This hybrid approach helps Einstein Copilot retrieve data based on its meaning or intent and ensure the right contextual data can be retrieved from Data Cloud for each prompt.
- The results from the search service are now used to augment the prompt through Prompt Builder. This new, augmented prompt includes the original user request together with all of the right contextual data.
- That prompt is then passed to the Einstein Trust Layer, Salesforce’s secure AI architecture. Now grounded with the contextual, timely data that it receives from the augmented prompt, an LLM called through the Einstein Trust Layer can generate trusted, relevant answers.
- Lastly, as part of the Einstein Trust Layer, the data that is ultimately used to inform the answer is called out in the output through citations, enabling the user to understand where the answer stemmed from.
Why is RAG useful?

- RAG empowers LLMs to use the most recent data while generating their response. Adding search results to a prompt reduces hallucinations in generative AI responses, without the complexity of fine-tuning or retraining an LLM.
- With RAG, generative AI responses can cite the source of their data. This brings transparency to the generation process and instills user trust.
- A majority (71%) of senior IT leaders think generative AI will introduce new security risks for data. With RAG, a company’s structured and unstructured data doesn’t need to be part of the LLM itself. The data is kept safe and secure by sending the augmented prompt through the Einstein Trust Layer, meaning specific data privileges are now respected, and LLM responses will never expose data to users who don’t have access to it.
- RAG allows customers to use standardized LLMs that are tested and proven and have ethics built-in, without sacrificing customer relevancy or domain specificity. It also facilitates the use of smaller LLMs, which are more cost-effective and sustainable.
How RAG is used across the Salesforce Customer 360
Using RAG patterns through Einstein Copilot Search and the Data Cloud Vector Database makes every Salesforce Customer 360 cloud and industry solution smarter.
- In Sales Cloud, every sales rep can use insights previously hidden in sales emails, previous meeting notes, call transcripts, company white papers, product documentation, and more. RAG can use data from all of those unstructured materials in Data Cloud to facilitate the creation of a meeting brief, helping reps quickly prepare for customer conversations based on all the relevant background information. RAG can also facilitate the use of this data in generating better emails and other outbound messages.
- In Service Cloud, every service rep can now see suggested replies based on knowledge articles, previous cases, conversation contexts, previous emails, and other unstructured data. This helps them answer customers faster and better through every channel.
- Across any industry and cloud, companies can ask questions about content from documents. For example, RAG enables exploration through question and answer of user manuals, product documentation, RFP documents, or even previous answers to RFQ questions.
Learn more
- Read the news about Salesforce’s new unstructured data capabilities and Einstein Copilot Search
- Learn more about Salesforce AI
- Find out how Einstein Copilot powers the enterprise in this interview