


A sigla ETL caracteriza uma tríade de processos extremamente importantes para a manutenção e o gerenciamento de dados. Ela significa EXTRAIR – TRANSFORMAR – CARREGAR. Nesse caso, o processo de extração se concentra na coleta de dados das diversas fontes disponíveis; a transformação está em transfigurar dados em informação relevante e, por fim, o ato de carregar está atrelado a transportar os dados para a warehouse de destino.
Assim, o ETL, para funcionar, usa uma variedade de regras para refinar dados brutos, dilapidando-os em informação sofisticada e aprofundada sobre clientes, colaboradores, usuários e tarefas. Inclusive, é através do ETL, que os dados são preparados para serem usados por IA e sistemas de machine learning.
Para saber mais sobre ETL, continue aqui Abaixo, os principais tópicos que serão abordados neste artigo. Boa leitura!
O que teremos pela frente:
Potencialize seu sucesso no varejo com dados e IA
Para manter a competitividade em um varejo em constante evolução, é fundamental usar dados e IA de forma estratégica. Descubra neste guia como conectar tecnologia e equipes para otimizar operações e aumentar o ROI.



LEIA MAIS: O que é Inteligência Artificial?
O que é ETL?
O processo de ETL (Extração, Transformação e Carregamento) consiste em reunir dados de diferentes fontes e integrá-los em um repositório centralizado, conhecido como data warehouse.
Durante essa etapa, aplica-se um conjunto de regras de negócios para limpar, organizar e preparar os dados brutos, tornando-os prontos para armazenamento, análise de dados e aplicações generativas e de IA.
Com isso, é possível atender a demandas específicas de business intelligence, como gerar relatórios e dashboards, prever impactos de decisões estratégicas, otimizar operações e muito mais.
LEIA MAIS: Conheça o único fator que define sucesso dos agentes de IA
Como funciona o processo de ETL?
O processo de ETL funciona como uma peça central na arquitetura de integração de dados. Por isso, ele está intimamente ligado a uma série de técnicas, tecnologias e práticas complementares que potencializam seu desempenho e abrangência.
Nesse sentido, a linguagem SQL (Structured Query Language) continua sendo o principal mecanismo para consulta e transformação de dados armazenados em bancos relacionais, servindo como base para muitas operações realizadas durante o processo de ETL.
Após a extração dos dados do sistema-fonte, são aplicadas transformações baseadas em regras de negócios específicas, a fim de converter os dados para um formato compatível com os requisitos do sistema de destino – que pode ser um software como um CRM, por exemplo.
Nesse contexto, o data mapping (ou mapeamento de dados) fornece instruções precisas sobre como os dados devem ser transformados e transferidos entre os sistemas. O mapeamento define claramente quais campos de origem correspondem a quais campos no destino. Todas essas explicações podem parecer um pouco complexas e abstratas, mas vamos ilustrar a seguir.
Por exemplo, considere dados oriundos de atividades em um site – seus próprios dados de navegação no blog da Salesforce podem ser usados como caso de estudo. Normalmente, no cenário on page, consideram-se:
- nome de usuário,
- horário de ação
- tempo de sessão
- páginas acessadas
Todos esses dados precisam ser organizados e filtrados – ou harmonizados e orquestrados – para se adequar à estrutura de um sistema de CRM, que pode armazenar apenas parte dessas informações e em uma ordem específica. Isso implica em transformações adicionais, como a formatação de datas ou a exclusão de atributos irrelevantes.
Além disso, vale atentar-se para a qualidade dos dados coletados. Geralmente, isso é outra etapa crítica dentro do processo de integração. Antes de os dados serem consolidados, geralmente são submetidos a uma fase de limpeza, padronização e verificação, em ambientes controlados.
Assim, nomes duplicados, formatos inconsistentes (por exemplo, “SP” vs. “São Paulo”) e endereços inválidos são corrigidos nessa fase. Hoje, essas etapas de data quality podem ser incorporadas diretamente às transformações do próprio pipeline de ETL.
Deu para perceber que estamos no boom dos dados, né?
Aprender mais sobre ETL reforçou ainda mais essa máxima. Então, para aprofundar seus conhecimentos sobre a moeda mais valiosa desta era (os dados!), confira o que Danielli Sousa, especialista da Salesforce, tem a falar sobre eles:
Por que o ETL é importante na integração de dados?
Com a implementação de processos digitais trespassando todas as áreas da empresa (ou, pelo menos, a maioria delas) e a popularização da IA e do uso de promprs, as organizações acabam tendo que lidar com uma ampla variedade de dados, tanto estruturados quanto não estruturados, provenientes de diversas fontes, como:
- Informações de clientes obtidas por meio de plataformas de pagamento online e sistemas de CRM (Customer Relationship Management);
- Dados operacionais e de inventário extraídos de sistemas utilizados por fornecedores;
- Leituras geradas por sensores conectados à Internet das Coisas (IoT);
- Interações em redes sociais e feedbacks de clientes;
- Registros internos de funcionários provenientes de sistemas de RH.
Por meio do processo de ETL, é possível consolidar e organizar esses dados brutos em formatos estruturados e padronizados, otimizando-os para análise e geração de insights. Portanto, essa preparação permite transformar dados dispersos em ativos analíticos úteis.
Por exemplo, empresas do varejo digital podem utilizar dados de vendas para prever tendências de consumo e ajustar seus estoques. Da mesma forma, times de marketing podem cruzar dados do CRM com comentários em redes sociais para entender melhor o comportamento e as preferências dos consumidores.
LEIA MAIS: Algoritmo: o que é e como funciona?
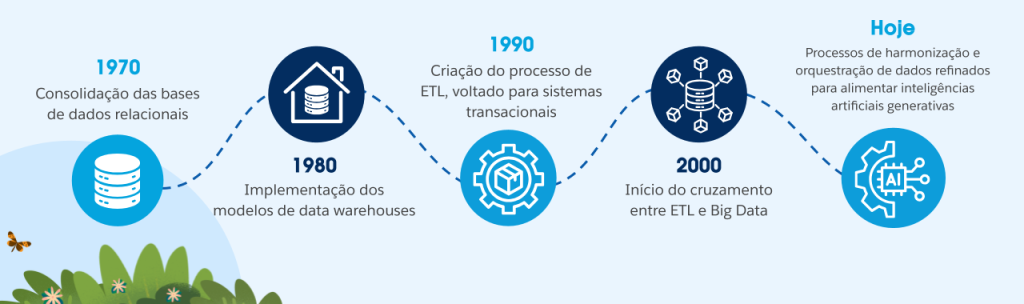
A evolução do processo de ETL
O processo de ETL surgiu, em um primeiro momento, com a popularização dos bancos de dados relacionais, que organizavam as informações em tabelas estruturadas para facilitar a análise. Inicialmente, as primeiras ferramentas de ETL tinham como principal objetivo converter dados oriundos de sistemas transacionais em formatos compatíveis com bancos relacionais, permitindo que esses dados fossem analisados de forma mais eficiente.
Entendendo o ETL tradicional
Em sua concepção original, o ETL atendia à necessidade de lidar com dados brutos armazenados em sistemas transacionais – estruturas otimizadas para operações frequentes de leitura e escrita, mas pouco adequadas para análises complexas. Imagine, por exemplo, um sistema de e-commerce em que cada transação registra o item comprado, os dados do cliente e as informações do pedido.
Com o tempo, acumula-se uma grande quantidade de registros redundantes, como múltiplas entradas para o mesmo cliente, que fez várias compras ao longo do ano. Esse tipo de duplicação tornava difícil extrair insights, como identificar os produtos mais vendidos ou compreender padrões de compra.
Para solucionar esse desafio, as ferramentas de ETL passaram a automatizar a transformação desses dados transacionais em estruturas relacionais mais otimizadas para análise. As tabelas passaram a ser interconectadas, permitindo aos analistas explorar relações entre os dados e identificar tendências com maior facilidade por meio de consultas estruturadas.
Como o ETL funciona hoje
Com a evolução tecnológica, tanto os formatos quanto as fontes de dados se diversificaram consideravelmente. A ascensão da computação em nuvem possibilitou o desenvolvimento de ambientes de armazenamento escaláveis, conhecidos como data collectors, capazes de reunir grandes volumes de dados oriundos de múltiplas fontes.
Entre os principais componentes desses ecossistemas modernos, destacam-se:
Data Warehouses
Os data warehouses funcionam como repositórios centralizados para a consolidação de múltiplos bancos de dados. Neles, os dados são organizados em tabelas e colunas, com uma estrutura bem definida que descreve os tipos de informação armazenados. Essas plataformas operam sobre diferentes tipos de hardware de armazenamento – como SSDs, HDs ou soluções em nuvem .
Os data lakes, por sua vez, oferecem maior flexibilidade ao permitir o armazenamento de dados estruturados, semiestruturados e não estruturados em um único repositório, e em qualquer volume. Diferente dos data warehouses, eles não exigem que os dados sejam previamente organizados com base em questões analíticas específicas.
Com essa abordagem, é possível executar diversos tipos de análise, incluindo consultas SQL, processamento de big data, buscas em texto completo, análises em tempo real e aplicações de machine learning, tudo a partir dos mesmos conjuntos de dados brutos.
Essa evolução no processo de ETL reflete uma necessidade crescente das organizações: transformar grandes volumes de dados diversos em insights acionáveis, com agilidade e precisão, aproveitando as capacidades das tecnologias modernas de armazenamento e processamento.
LEIA MAIS: IA + dados + CRM: Insights inovadores do diretor de engenharia para obter vantagem competitiva
ETL vs. ELT: quais as diferenças?
Nos últimos anos, o processo de integração e transformação de dados evoluiu consideravelmente. Junto com ele, surgiu uma nova sigla que vem ganhando espaço: ELT. Preste atenção: não é ETL, é ELT. Para quem já está familiarizado com o conceito de ETL (Extract, Transform, Load), trata-se do fluxo clássico em que os dados são extraídos de suas fontes, transformados em um formato padronizado e, só então, carregados para um destino final, como um data warehouse.
Através desse processo, garante-se a consistência e qualidade desde o início, mas também pode se tornar mais lento e custoso em ambientes com grandes volumes de dados ou necessidade de análises em tempo quase real.
Nesse sentido, o ELT (Extract, Load, Transform) inverte parte dessa lógica. Em vez de transformar os dados antes de carregá-los, o ELT primeiro os extrai e os carrega diretamente em um data lake ou data warehouse moderno para depois realizar as transformações dentro da própria infraestrutura de destino.
Assim, essa abordagem aproveita o poder de processamento dessas plataformas em nuvem, que são escaláveis e otimizadas para lidar com grandes quantidades de dados de forma paralela e eficiente.
A principal diferença entre ETL e ELT, portanto, está no momento e no local onde as transformações ocorrem. Enquanto o ETL é ideal quando há necessidade de um controle rigoroso de qualidade antes do carregamento (como em sistemas legados ou bancos de dados on-premise), o ELT é mais indicado para cenários de big data e análises avançadas, em que a agilidade e a flexibilidade para manipular dados brutos são prioritárias.
Em resumo, a escolha entre ETL e ELT depende menos de “qual é melhor” e mais de qual se encaixa melhor na arquitetura e nos objetivos de negócio. Empresas que ainda operam com sistemas tradicionais podem continuar se beneficiando do ETL, especialmente quando a governança e a padronização são cruciais.
Por outro lado, organizações que investem em nuvem e precisam de rapidez para gerar insights podem tirar mais proveito do ELT. Em um cenário de dados cada vez mais distribuído e dinâmico, compreender essa diferença é essencial para desenhar pipelines escaláveis, eficientes e alinhadas à estratégia da empresa.
LEIA MAIS: Treinar modelos de IA não vai te ajudar a conquistar clientes, dados vão
Como escolher a ferramenta certa de ETL?
Em um cenário onde os dados se tornaram o centro das decisões estratégicas, escolher a ferramenta de ETL (Extract, Transform, Load) certa é um passo essencial. Com uma ampla oferta de soluções, a escolha precisa levar em conta muito mais do que custo ou popularidade. É fundamental alinhar a ferramenta ao porte da empresa, à infraestrutura existente e à maturidade da estratégia de dados.
O ponto de partida é compreender as demandas específicas do seu ecossistema de dados. Organizações que processam grandes volumes ou trabalham com múltiplas fontes e formatos precisam de soluções escaláveis e de alta performance. Já empresas em estágios iniciais podem priorizar ferramentas mais intuitivas e de rápida adoção.
Além disso, ferramentas como o Mulesoft se destacam em diferentes contextos: enquanto algumas se integram de forma nativa com data lakes e warehouses em nuvem, outras são mais fortes em integração entre sistemas corporativos e APIs.
Outro critério essencial é equilibrar facilidade de uso com flexibilidade e controle. Soluções open source, como Apache NiFi e Airbyte, oferecem liberdade de customização, mas exigem uma equipe técnica capacitada para manutenção e orquestração. Já plataformas gerenciadas e SaaS reduzem a carga operacional, automatizando grande parte do pipeline de dados.
A Mulesoft, por exemplo, tem se destacado nesse cenário por unir integração de dados com conectividade entre aplicações, APIs e sistemas legados – um diferencial importante para empresas que desejam construir uma visão unificada e segura de seus dados sem comprometer a governança.
Por fim, é crucial avaliar escalabilidade, custos e suporte. Uma escolha feita apenas com base nas necessidades atuais pode se tornar um gargalo no futuro. Portanto, verifique se a solução cresce junto com o negócio, se oferece suporte técnico robusto e se possui uma comunidade ativa.
No fim das contas, a ferramenta de ETL ideal é aquela que combina desempenho, integração e confiabilidade, permitindo que a equipe extraia valor real dos dados. Mais do que uma decisão técnica, trata-se de um investimento estratégico que sustenta o crescimento e a inteligência analítica da organização.
LEIA MAIS: Quality Assurance: o que é e qual a importância?
FAQ: perguntas frequentes sobre ETL
ETL é um processo que envolve a extração, transformação e carga de dados entre sistemas. Ele é usado para consolidar dados de diferentes fontes em um repositório único, como um data warehouse, facilitando a análise e a tomada de decisões.
No ETL, os dados são transformados antes de serem carregados no destino. Já no ELT, a transformação ocorre após o carregamento, aproveitando o poder de processamento do próprio banco de dados. A escolha depende da arquitetura e da performance desejada.
O ETL melhora a qualidade dos dados, permite integração entre sistemas distintos e facilita a criação de relatórios analíticos. Ele também automatiza o fluxo de dados, reduzindo erros manuais e aumentando a eficiência no uso da informação.
Ferramentas como Mulesoft e algumas ferramentas da Informatica, recentemente adquirida pela Salesforce, são comumente usadas. Elas ajudam a orquestrar o processo de ETL com conectores prontos, interface gráfica e suporte a diferentes tipos de dados e formatos.
Não. Qualquer empresa que trabalhe com múltiplas fontes de dados pode se beneficiar do ETL. Mesmo em pequenas empresas, ele ajuda a centralizar informações, padronizar dados e gerar insights de forma mais organizada e confiável.
LEIA MAIS: Clusters: o que são e para que servem?
O que você achou de saber mais sobre ETL?
Nosso blog e Centro de Recursos sempre estão atualizados com novidades e conteúdos sobre CRM, Dados e Inteligência Artificial. Confira algumas leituras que também podem ser úteis para você:
- Quality Assurance: o que é e qual a importância?
- Análise de dados: como fazer corretamente?
- Outsourcing: o que é e quando terceirizar?
- O que é SaaS (Software as a Service)?
Aproveite para entender como sua empresa pode potencializar negócios com uma combinação de dados e IA.
Bom trabalho e até a próxima!
Desbloqueie o potencial dos dados não estruturados para impulsionar sua estratégia de IA
















