



What if launching an RL training run felt less like operating a GPU cluster and more like talking to a sharp research engineer in Slack?
Training AI models is still strangely artisanal, involving tedious infrastructure handling as we outlined in our SFR-RL stack. If you are an AI researcher or engineer, you know the loop: find or clean a dataset, pick a reward (for RL), tune a launch script, submit a job, babysit logs, compare checkpoints, write a report, tweak one flag, and do it again. If the target is an agent, the loop gets even harder: now you need harness, rollout environments, tools, simulators, LLM judges, trajectory analysis, and deployment tests.
At Salesforce AI Research, we have developed SFR-VibeTrain to make that loop conversational, and eventually almost self-moving. VibeTrain is a messaging-native agentic control plane for AI model and agent training. You describe what you want to train, upload data if you have it, or just describe the problem if you do not. VibeTrain reasons about your training task, consults recent literature when useful, prepares the training artifacts, launches the job, analyzes the run, proposes the next experiment, and can deploy the resulting agent back into the same workspace.
Not a dashboard. Not a thin wrapper around a fine-tuning API. Instead, a conversational training agent that can use tools, write code, inspect metrics, and iterate with you.
Demo video: a customer-retention agent is failing, the user has no labeled training data, and VibeTrain turns the failure into synthetic scenarios, a simulator, a judge, an agentic RL run, evaluation and deployment.

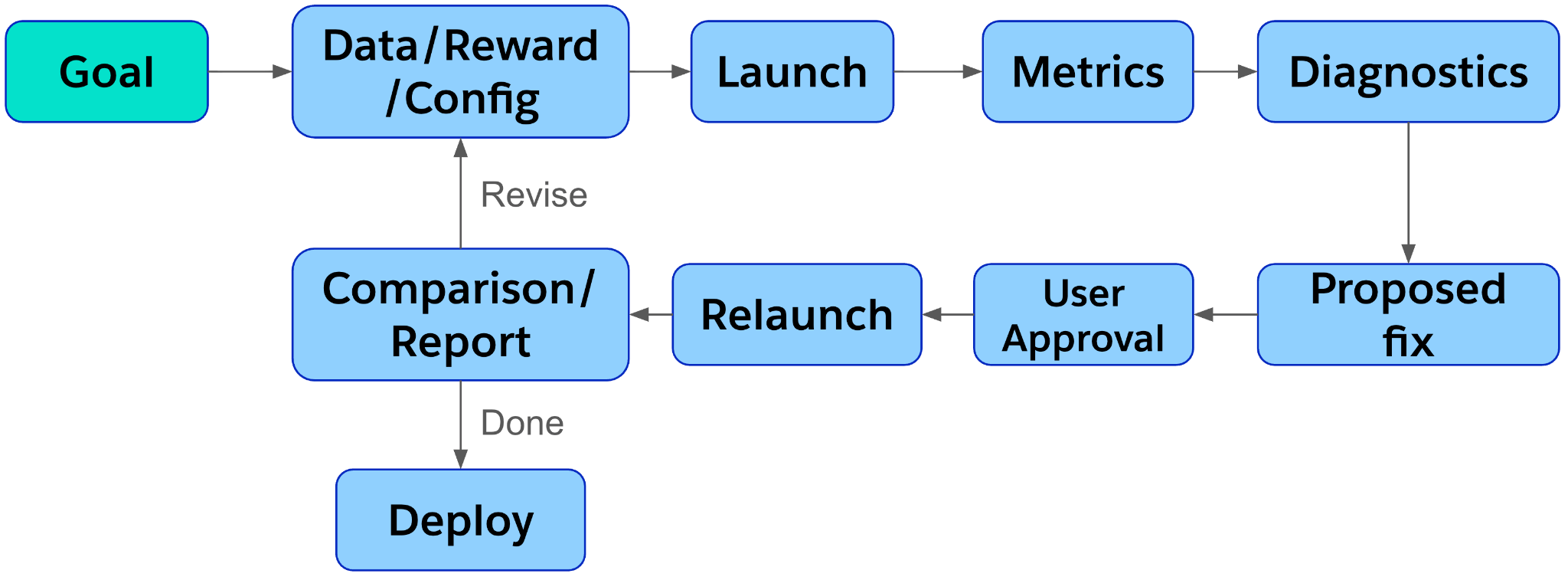
The Training Stack Should Talk Back
Instead of asking a user to know every low-level detail up front, VibeTrain can ask and answer questions like:
- What kind of task is this dataset actually describing?
- What datasets might be suitable for a task in hand?
- Is this a supervised fine-tuning problem, an RL problem, or an agentic RL problem?
- What reward should we use?
- Does recent literature already have a method for this?
- What hardware footprint is reasonable for this model?
- Did this run fail because the reward is bad, the groups are filtered too aggressively, entropy collapsed, KL is missing, or responses are hitting the length cap?
- What is the next clean ablation?
The user stays in the loop for expensive or irreversible actions. VibeTrain does the reversible work: inspect, transform, draft, plot, summarize, propose.
What VibeTrain Does
At a high level, VibeTrain turns casual user intent into executable training work.
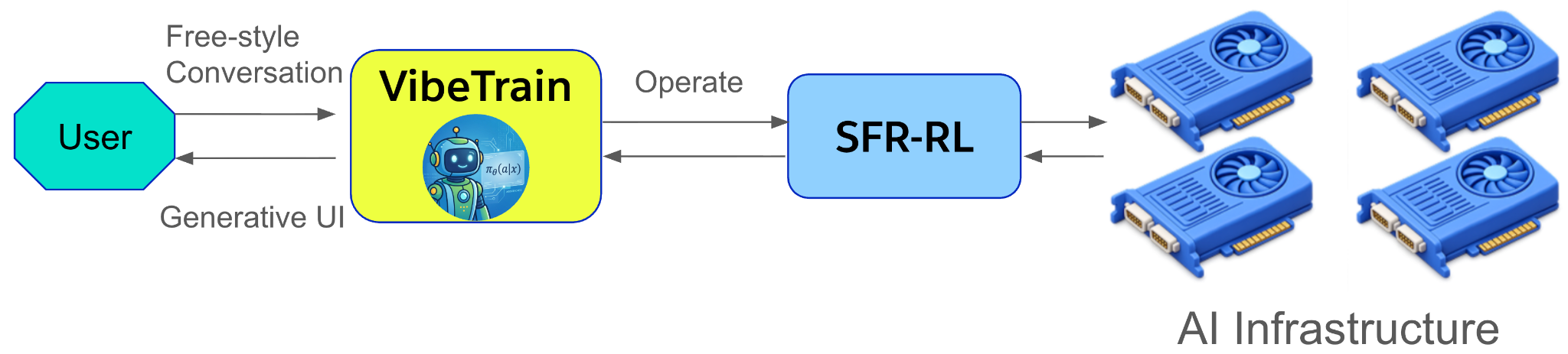
VibeTrain sits above the training stack (e.g., our SFR-RL stack) as a messaging-native agentic control plane: conversation, tools, skills, distributed training, experiment artifacts, reports, and deployment.
For example, for a dataset-driven task, it turns this:

For an agent-improvement task, it turns this:

Under the hood, VibeTrain has access to:
– Web tools
– Coding tools
– Relevant Skills
– Access to Our efficient and high-throughput distributed training stack SFR-RL
The current prototype is implemented inside Slack, but Slack is not the core idea. The core idea is a stateful, artifact-aware messaging interface for the full model-training lifecycle.
Why This Is Different
Most training products make one part of the workflow easier. VibeTrain tries to own the whole arc from intent to experiment to deployed agent.
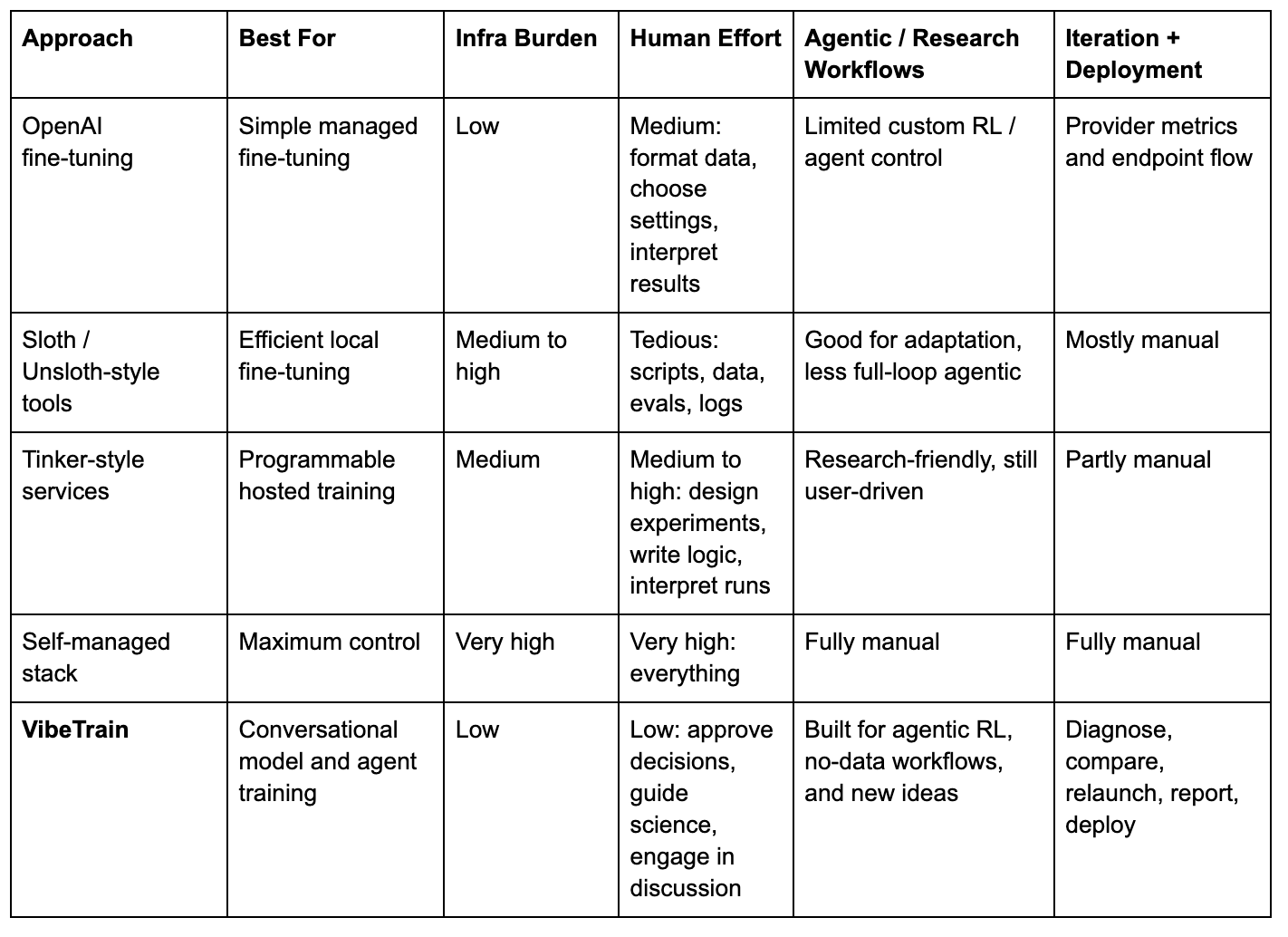
The point is not that VibeTrain replaces every training stack. It sits above them. It turns the stack into something a researcher or engineer can collaborate with.
Use Case 1: A Researcher Starts From a Dataset
The first demo video shows the simplest entry point: a researcher already has data, but does not want to become the integration layer between the dataset, reward, launch script, GPU cluster, metrics dashboard, and final report.
A researcher uploads a math dataset, asks VibeTrain to train with RL, reviews the generated training plan, approves launch, returns later for run analysis, accepts a suggested fix, launches run #2, compares the runs, and asks for a progress deck.
The key moment in the video is the handoff from “I have a dataset” to “I have a runnable experiment.” VibeTrain inspects the file, infers the task, proposes the training recipe, prepares artifacts and launches. Later, VibeTrain diagnoses the run, suggests the next experiment, launches the follow-up, compares results, and generates the report.
This is the workflow many AI researchers already do manually. VibeTrain makes it conversational, inspectable, and repeatable.
Use Case 2: An Engineer With No Dataset
This is not a standard fine-tuning workflow. The user is not saying “here is my labeled dataset.” The user is saying “this agent behaves badly, here is an example, can we teach it the right behavior?”
The demo video about “customer-retention agent” above demonstrates this use case.
VibeTrain treats that as task design. It reasons about the behavioral failure, proposes what the trained policy should learn, creates the data and evaluation setup, and turns a messy product problem into an executable agent-training workflow.
That is where a conversational training agent becomes more than convenience. It can help define the training problem itself.
Use Case 3: Research Ideas, Not Just Runs
Researchers rarely start with a clean product requirement. They start with an idea:
- What if we change the advantage estimator?
- What if the loss should be sequence-level instead of token-level?
- What if we reward tool-use behavior differently?
VibeTrain is designed to engage in that kind of discussion.
Because it has web access, it can consult public resources. It can compare the user’s idea against existing methods, suggest baselines, propose an experiment plan, and then edit code or launch configs to run the experiment.
This matters for AI research. A lot of research time is not spent thinking about the idea. It is spent turning the idea into a runnable experiment. VibeTrain aims to compress that path.

That is the kind of interaction we want: technical, concrete, and executable.
The Closed Loop: Run Ablations, Compare, Learn
Training agents is noisy. A run can look promising early and still go sideways later.
VibeTrain is designed to turn that question into an ablation loop. It can analyze a run, propose useful changes, launch a follow-up, and then conduct comparison. Instead of leaving the researcher to stitch together plots and notes by hand, VibeTrain can generate the comparison view on demand.
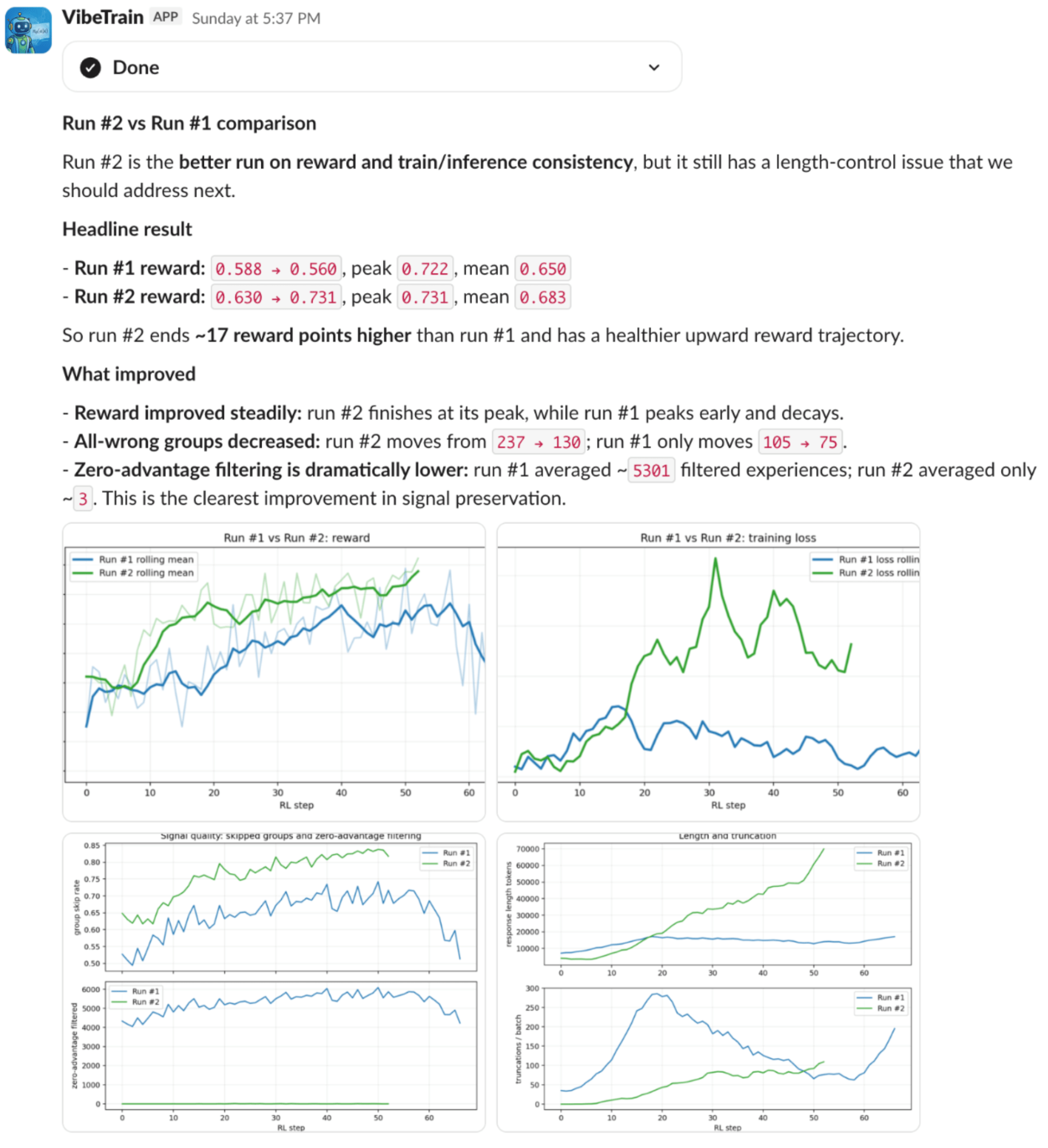
This turns experiment iteration into a real research loop the next experiment built on top of previous ones.
This is also where generative UI matters. The interface is not a fixed dashboard with a predetermined set of panels. The user asks a question, and VibeTrain creates the charts, tables, or slide-ready summaries.
That is the product difference. Fine-tuning tools usually stop at “job complete.” VibeTrain keeps going until the experiment has taught the team something actionable.
Reports Should Be Dynamically Generated, Not Hand-Assembled
Every training loop ends with communication. Researchers need to tell the team what changed, what worked, what failed, and what should happen next.
VibeTrain turns that communication into a generated artifact. A quick status update, failure analysis, run comparison, or team briefing can be produced directly from the experiment thread, with the right plots, interpretation, and recommended next steps.
The result is shared understanding. The analysis is not trapped in one researcher’s notebook or terminal scrollback; it becomes something the team can read, discuss, and act on.
Why This Matters
Agent training is becoming a team workflow, not just a model-training job.
The work now includes long-horizon behavior, tool use, simulations, evaluation, reporting, and deployment. Each step creates context the next step depends on. If that context is scattered across dashboards, notebooks, terminals, and meetings, the team loses momentum.
VibeTrain keeps the workflow in one shared conversation. The same place where a failure is reported can become the place where the plan is written, the run is launched, the curves are interpreted, the results are shared, and the trained model is tested.
Researchers can move from idea to experiment faster. Engineers can turn product failures into training workflows without becoming RL infrastructure experts. Teams can move from “the agent is broken” to “here is the evaluated replacement” with the reasoning, artifacts, and decisions visible along the way.
What We Are Building Toward
AI model training should not require every practitioner to become an expert in every layer of the stack before running one meaningful experiment.
Training should feel like collaboration. That is SFR-VibeTrain.






















