The data platforms built over the last two decades were designed for human analysts who could fill in the gaps. They knew which columns mattered, what the business logic behind a metric really was, when a number looked wrong, and how to read the email thread or call transcript that explained why. An AI agent operating autonomously has none of that context. It needs business meaning made explicit, governed, and machine-readable, not embedded in the heads of your data team.
Legacy modeling paradigms like third normal form (3NF), Dimensional Modeling, Data Vault, still work well when your workload is stable, reporting requirements are predictable, and no agentic use cases are on your roadmap. But the moment an agent tries to query, reason over, or act on your data without human intervention, legacy models introduce systemic friction that compounds fast.
Three failure modes show up consistently:
- Semantic gaps: Legacy models map structural relationships, like primary and foreign keys, but do not encode business logic. An agent cannot reliably deduce the operational meaning of a 3NF schema without heavy system prompting, where that prompting breaks the moment the schema changes.
- Rigid schemas: Dimensional models typically require predefined Extract, Transform, Load (ETL) access paths. Agents construct ad hoc, multidomain queries at runtime and must pivot their reasoning on the fly.
- Unstructured bias: Legacy models cannot natively operationalize the unstructured context, including emails, transcripts, and PDFs, that agents rely on for nuanced decisions.
A Semantic Data Model addresses all three. It is a governed translation layer that defines business logic over raw data in a form that both humans and agents can rely on. Instead of forcing an agent to guess which columns calculate churn risk, you define the logic once in the semantic layer. That definition becomes the single source of truth across the organization. When an agent triggers a workflow and an analyst reads a BI report, they evaluate the exact same governed logic. Security controls, access policies, and dynamic data masking are embedded in the semantic definitions, making governance structural rather than a brittle downstream filter an agent can bypass.
This post covers how to build that foundation, from physical storage to security and interoperability, using Salesforce Data 360.
Decouple storage from semantic logic using open table formats
Legacy architectures require architects to over-engineer physical schemas because storage and compute were tightly coupled. The schema has to carry the weight of organization, performance, and query optimization all at once.
Open table formats like Apache Iceberg remove that constraint by decoupling storage from compute. Structured rows, unstructured PDFs, call transcripts, and images can coexist in the same storage layer without being locked into a predefined schema. The physical organization of your data no longer determines how you model its meaning.
An agent navigating your data estate should never need to know how or where data is physically stored. Build the Semantic Data Model directly on top of raw storage so that governed meaning, not raw schema, is what the agent works from
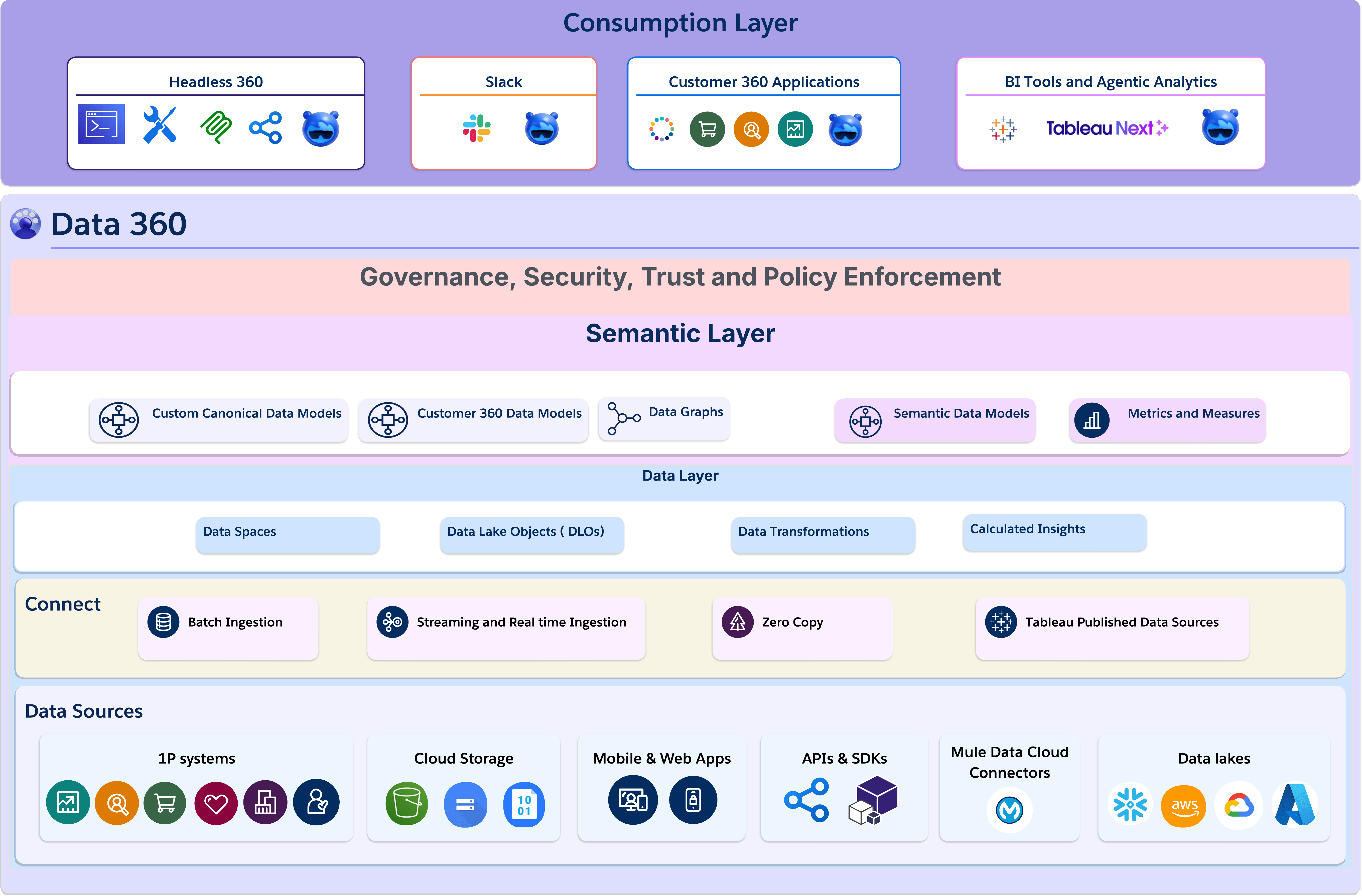
Implement the semantic layer using Salesforce Data 360
Salesforce Data 360 brings the Semantic Data Model to life. Built natively on Apache Iceberg, it functions as a scalable semantic and metadata layer, harmonizing enterprise data without the ETL overhead of legacy architectures. The semantic layer is known as Tableau Semantics across the platform.
The sections below walk through its key components: how raw data maps to governed business meaning, how unstructured data joins the same semantic graph, and how that foundation serves both agents and human analysts from a single governed definition.
Go deeper on Data 360 architecture
Explore the full DLO-to-DMO mapping process, Data Graph configuration, and the standard Customer 360 Data Model schema in detail.



Map raw data to business meaning using the Customer 360 Data Model
Data 360 is metadata-driven by design. Raw structured data lands in Data Lake Objects (DLOs) at the ingestion layer. DLOs are deliberately context-free physical storage that holds data without imposing any business logic on it. To build the semantic model, architects map those DLOs to Data Model Objects (DMOs), where they define meaning.
DMOs form the canonical Customer 360 Data Model: a prevalidated semantic foundation covering entities like the Engagement Data Model and Privacy Data Model, while being fully extensible. You can extend standard DMOs or create custom canonical models to reflect your enterprise topology, without having to rebuild the governed foundation underneath.
Data Graphs sit at the top of the stack as the delivery mechanism for the AI layer: pre-assembled, low-latency snapshots of the semantic graph that agents can retrieve at subsecond speed without ad-hoc query overhead. The architectural rule is very clear:: expose Data Graphs and DMOs to the AI layer, never raw DLOs. If you were to pass raw database objects (DLO) to an LLM directly, you strip away the join logic, metric definitions, and business rules the semantic layer provides, increasing the likelihood of hallucinations.
As a simple example of how this works in practice, take two metrics every revenue team depends on: Lifetime Value (LTV) and Annual Recurring Revenue (ARR). In a legacy model, both are typically calculated ad hoc — in a dashboard filter, a SQL view, or an analyst’s notebook. The semantic layer defines them once, by mapping relevant attributes from DLO and calculated insights centrally, and making them available as governed DMO attributes. The ARR formula, including any business rules that govern its calculation, is defined once as a calculated insight. Every agent, every report, and every workflow can read from that single DMO definition.
Extend the semantic graph to unstructured data
Structured data alone is not enough for agentic reasoning. Agents frequently need context that lives in emails, call transcripts, PDFs, and images — content that legacy architectures have no way to meaningfully connect to structured customer records. Data 360 handles this through a dedicated unstructured pipeline.
Ingest and process
Unstructured files are ingested into Unstructured Data Lake Objects (UDLOs) from sources including Amazon S3, Google Cloud Storage, Azure Blob Store, SharePoint, Zendesk, and Google Drive. The Data 360 engine processes each file producing:
- Extracted metadata
- Vector embeddings
- Chunked content for retrieval
Map into the semantic graph
The extracted content and metadata artifacts (file name, file size, type, and so on) map natively into the same DMO framework. The extracted content is mapped into an unstructured data model object (UDMO) as unstructured data and the artifacts as structured data. The result of connecting the UDMO and DMO by foreign keys is a unified semantic graph that gives agents multimodal context for retrieval-augmented generation (RAG)-driven interactions.
Native RAG capability
Data 360 includes a native RAG capability with:
- Semantic vector search combined with keyword search
- Dynamic retriever filters
- Visual data in RAG responses
- A retriever playground for end-to-end testing
The unified semantic graph in practice
The value of combining structured and unstructured context in the same semantic graph becomes clear at the moment an agent has to act. Consider an agent responsible for triggering renewal workflows. Before it acts, it runs a vector search across the customer’s support history, surfacing a transcript where the customer flagged a billing issue three weeks earlier. That unstructured context maps into the same semantic graph as the structured ARR and LTV definitions, giving the agent the full picture before it decides whether to proceed, escalate, or flag for human review.
Serve the same governed logic to humans and agents through Tableau Next
The same semantic layer that powers your agents also serves your human analysts. Data 360 functions as a headless BI layer that natively powers Tableau Next, with calculated insights as the core architectural mechanism. Calculated insights are complex, multidimensional formulas, such as Customer Lifetime Value or Pipeline Velocity, defined centrally on top of the Customer 360 Data Model and decoupled from individual dashboards.
This is where shared meaning becomes operational. When a human analyst asks Tableau Next for a natural-language breakdown of “Q3 Engagement,” and an Agentforce agent evaluates that same calculated insight to trigger a workflow, they query the exact same governed logic. The definition lives once. Both consumers read from it.
Extend semantic governance to external platforms using zero copy federation
Not all enterprise data lives in Salesforce, and physically ingesting everything creates a duplication problem that a semantic layer is designed to prevent. Zero copy data federation provides this semantic layer by querying external platforms directly at the storage layer, with no data movement required. Query federation and file federation both mount external tables as DLOs that map into the same semantic DMO graph, so the federation mechanism doesn’t change the architectural pattern.
A zero copy federated query does not copy data; it executes against the source directly, on terms set by the semantic model. The DMO that maps over an external table carries the definition forward, including the business logic, field-level lineage, and trust classification, without taking ownership of the underlying data.
This is how Data 360 extends semantic governance to external platforms, by resolving definitions at the model layer regardless of where the data physically resides. The semantic layer exists to enforce one definition, one lineage chain, one governed understanding of what a metric means.
Salesforce’s own Customer Zero implementation is the proof point. A multi-org Data 360 strategy built on Data Cloud One, it standardizes identity resolution, semantic models, and governance across business units while each org retains federated autonomy. You don’t need a monolithic migration to achieve semantic consistency. Govern centrally; stay flexible at the edges.
The interoperability story extends further. Salesforce co-leads the Open Semantic Interchange (OSI) initiative alongside Snowflake, dbt Labs, Databricks, BlackRock, and 20+ partners. OSI is a vendor-neutral, YAML-based open-source standard for universally interoperable semantic models, metrics, and relationships, with the core spec finalized in February 2026. Vendors are currently building the transformers needed for bidirectional interoperability. In the meantime, architects can bridge semantic systems today using platform APIs, with tools like Claude, Codex, or Cursor, generating translation code without waiting for native vendor tooling.
The roadmap also includes Bring Your Own Semantic (BYOS), the ability to import external semantic layers (for example, from Snowflake or database build tool) directly into Data 360, eliminating the need to redefine logic that already exists elsewhere. Whether an Agentforce agent, a custom LLM, or a third-party BI tool is querying your data stack, they will read the same OSI-compliant semantic logic, reducing the risk of vendor lock-in and semantic fragmentation.
Expose the full platform including the semantic layer to any agent or tool using Headless 360
Headless 360 reframes how the Salesforce platform is consumed. Every capability is now accessible via an API, a Model Context Protocol (MCP) server, or a Command Line Interface (CLI), with no browser or UI required. Any agent, any model, any tool can connect to Salesforce data and processes directly.
That flexibility demands a coherent foundation. When any tool can connect to anything, the architecture underneath determines whether those connections produce reliable results or compounding inconsistency.
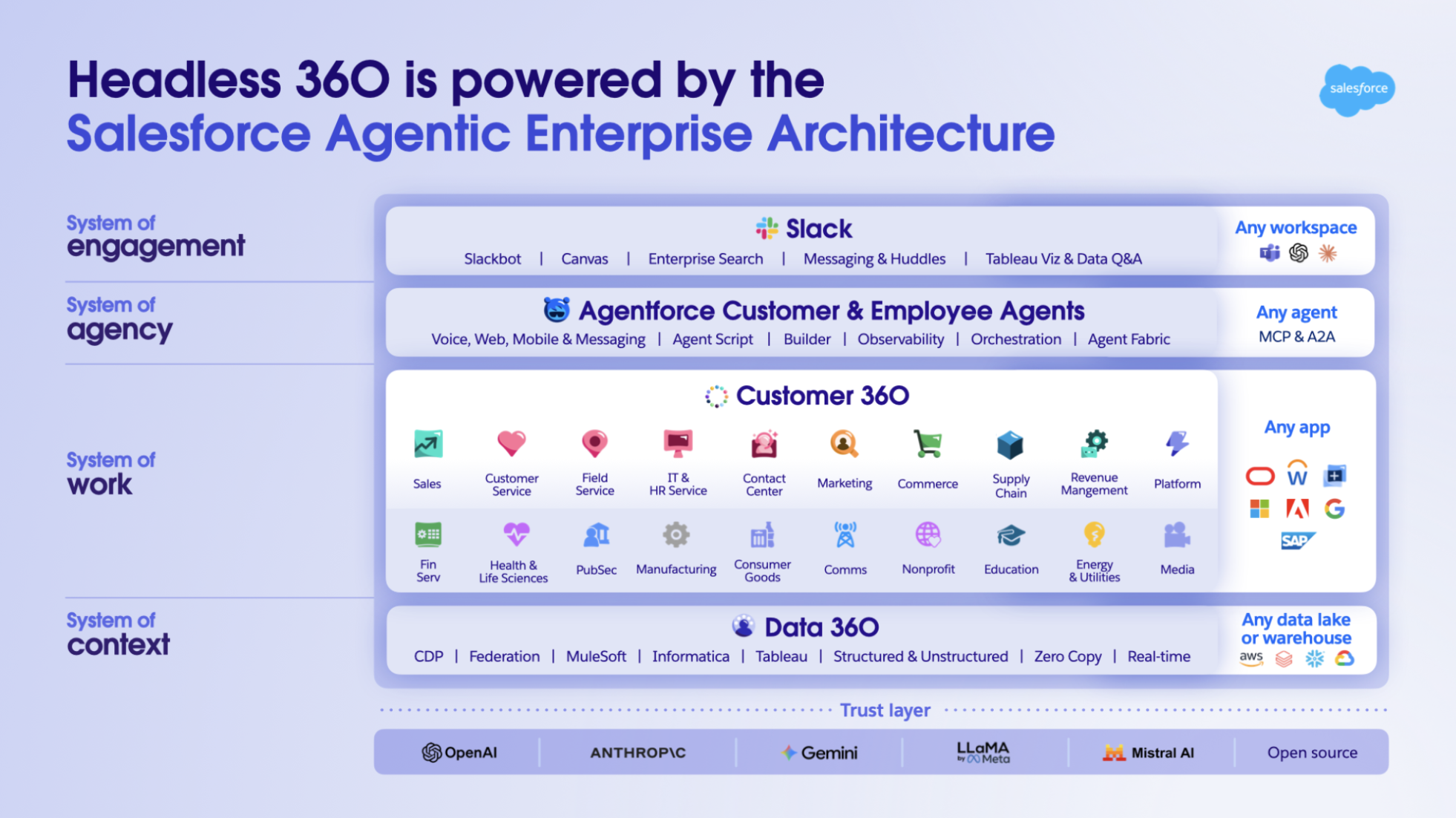
The architecture that powers Headless 360 is organized into four layers. Data 360 sits at the base for a reason. Without a governed semantic layer underneath, business logic has nothing solid to work with. Agents will infer rather than know, and what surfaces to users may simply be wrong. As more tools connect via MCP, that foundation becomes more critical, not less.




Six principles for maintaining your semantic foundation
The sections above describe how to build a governed semantic foundation on Data 360. The following six principles are how you maintain it as agents, tools, and integrations multiply around it:
- Define once, govern always: Every entity an agent reasons over needs a canonical DMO definition, not an ad hoc mapping built downstream in a prompt or dashboard. Without it, different agents calculate the same metric in conflicting ways and trust in autonomous operations erodes fast. This is the Well-Architected foundation: governed definitions are what make agent outputs verifiable.
- Federate, don’t duplicate: Use zero-copy federation across multi-cloud platforms instead of physical data pipelines. Data duplication breaks the semantic chain and introduces synchronization delays. A Well-Architected data platform has a single semantic source of truth regardless of where data physically resides.
- Treat the semantic contract as a first-class asset: Version DMO mappings and data space boundaries as rigorously as application code. In Well-Architected terms, a versioned semantic contract is what decouples architectural change from downstream breakage.
- Ground agents in the semantic layer, not in raw SQL: Pass governed DMOs and data graphs for structured context, and vector search results for unstructured knowledge. Passing raw SQL strips away business logic and forces the model to infer context, leading to unpredictable reasoning and security vulnerabilities. A Well-Architected AI layer enforces governed access at runtime, not just at definition time.
- Make the metadata layer intelligent: Enrich agents with org-specific semantic context through the Unified Metadata layer. Agents require not just the structural layout of your tables, but explicit definitions of business meaning, relationships, and usage rules. A Well-Architected semantic model makes governed definitions discoverable to agents and humans without bespoke integration work for every new consumer.
- Design for interoperability, not just integration: Adopt OSI-compliant semantic definitions from the start. A Well-Architected semantic layer ensures governed business logic travels with your data as the AI ecosystem expands via MCP and Headless 360, not locked to a single tool or interface.
The place to start is your most critical business entity. Define it as a canonical DMO within Salesforce Data 360. That is your first semantic contract, and the foundation everything else builds from.
Next, continue building your semantic foundation.The Data 360 for Architects Trail on Trailhead walks through the full data model, federation, and governance patterns in detail.
Subscribe to the Salesforce Architect Digest on LinkedIn
Get monthly curated content, technical resources, and event updates designed to support your Salesforce Architect journey.