How To Unlock the Power of Generative AI Without Building Your Own LLM

Large language models are the foundation for today's groundbreaking AI applications. Instead of training an LLM on a massive dataset, save time by using an existing model with smart prompts grounded in your data. Here’s how.

Everyone wants generative AI applications and their groundbreaking capabilities, such as creating content, summarizing text, answering questions, translating documents, and even reasoning on their own to complete tasks.
But where do you start? How do you add large language models (LLMs) to your infrastructure to start powering these applications? Should you train your own LLM? Customize a pre-trained open-source model? Use existing models through APIs?
Training your own LLM is a daunting and expensive task. The good news is that you don’t have to. Using existing LLMs through APIs allows you to unlock the power of generative AI today, and deliver game-changing AI innovation fast.
How can a generic LLM generate relevant outputs for your company? By adding the right instructions and grounding data to the prompt, you can give an LLM the information it needs to learn “in context,” and generate personalized and relevant results, even if it wasn’t trained on your data.
Your data belongs to you, and passing it to an API provider might raise concerns about compromising sensitive information. That’s where the Einstein Trust Layer comes in. (More on this later.)
In this blog post, we’ll review the different strategies to work with LLMs, and take a deeper look at the easiest and most commonly used option: using existing LLMs through APIs.
What is an LLM?
Large language models (LLMs) are a type of AI that can generate human-like responses by processing natural-language inputs. LLMs are trained on massive datasets, which gives them a deep understanding of a broad context of information. This allows LLMs to reason, make logical inferences, and draw conclusions.



As Salesforce’s SVP of technical audience relations, I often work with my team to test things out around the company. I’m here to take you through each option so you can make an informed decision.
1. Train your own LLM (Hint: You don’t have to)
Training your own model gives you full control over the model architecture, the training process, and the data your model learns from. For example, you could train your own LLM on data specific to your industry: This model would likely generate more accurate outputs for your domain-specific use cases than a general-purpose model.
But training your own LLM from scratch has some drawbacks, as well:
- Time: It can take weeks or even months.
- Resources: You’ll need a significant amount of computational resources, including GPU, CPU, RAM, storage, and networking.
- Expertise: You’ll need a team of specialized Machine Learning (ML) and Natural Language Processing (NLP) engineers.
- Data security: LLMs learn from large amounts of data — the more, the better. Data security in your company, on the other hand, is often governed by the principle of least privilege: You give users access to only the data they need to do their specific job. In other words, the less data the better. Balancing these opposing principles may not always be possible.
2. Customize a pre-trained open-source model (Hint: You don’t have to)
Open-source models are pre-trained on large datasets and can be fine-tuned on your specific use case. This approach can save you a lot of time and money compared to building your own model. But even though you don’t start from scratch, fine-tuning an open-source model has some of the characteristics of the train-your-own-model approach: It still takes time and resources, you still need a team of specialized ML and NLP engineers, and you may still experience the data security tension described above.
3. Use existing models through APIs
The last option is to use existing models (from OpenAI, Anthropic, Cohere, Google, and others) through APIs. It’s by far the easiest and most commonly used approach to build LLM-powered applications. Why?
- You don’t need to spend time and resources to train your own LLM.
- You don’t need specialized ML and NLP engineers.
- Because the prompt is built dynamically into users’ flow of work, it includes only data they have access to.
The downside of this approach? These models haven’t been trained on your contextual and private company data. So, in many cases, the output they produce is too generic to be really useful.
A common technique called in-context learning can help you get around this. You can ground the model in your reality by adding relevant data to the prompt.
For example, compare the two prompts below:
Prompt #1 (not grounded with company data):
Write an introduction email to the Acme CEO.
Prompt #2 (grounded with company data):
You are John Smith, Account Representative at Northern Trail Outfitters.
Write an introduction email to Lisa Martinez, CEO of ACME.
Acme has been a customer since 2021.
It buys the following product lines: Edge, Peak, Elite, Adventure.
Here is a list of Acme orders:
Winter Collection 2024: $375,286
Summer Collection 2023: $402,255
Winter Collection 2023: $357,542
Summer Collection 2022: $324,573
Winter Collection 2022: $388,852
Summer Collection 2021: $312,899
Because the model doesn’t have relevant company data, the output generated by the first prompt will be too generic to be useful. Adding customer data to the second prompt gives the LLM the information it needs to learn “in context,” and generate personalized and relevant output, even though it was not trained on that data.
The more grounding data you add to the prompt, the better the generated output will be. However, it wouldn’t be realistic to ask users to manually enter that amount of grounding data for each request.
Luckily, Salesforce’s Prompt Builder can help you write these prompts grounded in your company data. This tool lets you create prompt templates in a graphical environment, and bind placeholder fields to dynamic data that’s available through the Record page, flows, Data Cloud, Apex calls, or API calls.

But adding company data to the prompt raises another issue: You may be passing private and sensitive data to the API provider, where it could potentially be stored or used to further train the model.
Use existing LLMs without compromising your data
This is where the Einstein Trust Layer comes into play. Among other capabilities, the Einstein Trust Layer lets you use existing models through APIs in a trusted way, without compromising your company data. Here’s how it works:
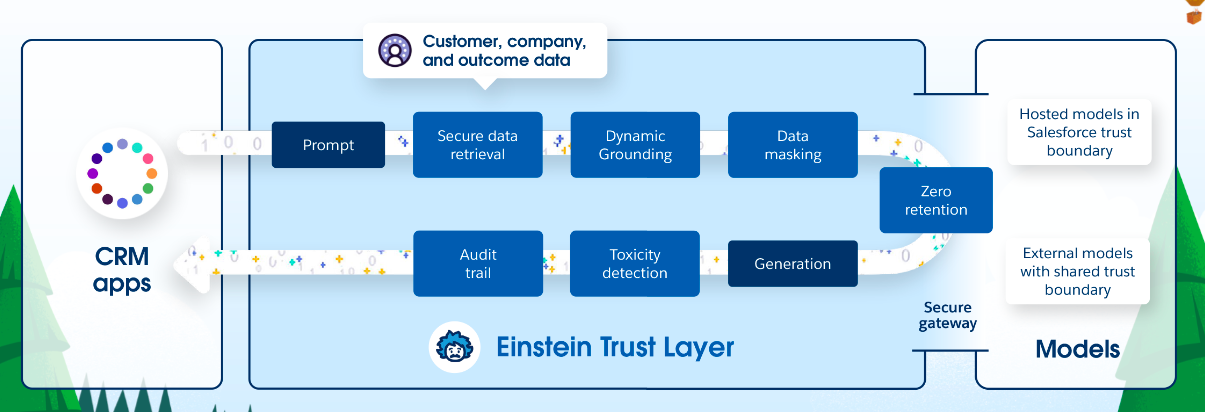
- Secure gateway: Instead of making direct API calls, you use the Einstein Trust Layer’s secure gateway to access the model. The gateway supports different model providers and abstracts the differences between them. You can even plug in your own model if you used the train-your-own-model or customize approaches described above.
- Data masking and compliance: Before the request is sent to the model provider, it goes through a number of steps including data masking, which replaces personal identifiable information (PII) data with fake data to ensure data privacy and compliance.
- Zero retention: To further protect your data, Salesforce has zero retention agreements with model providers, which means providers will not persist or further train their models with data sent from Salesforce.
- Demasking, toxicity detection, and audit trail: When the output is received from the model, it goes through another series of steps, including demasking, toxicity detection, and audit trail logging. Demasking restores the real data that was replaced by fake data for privacy. Toxicity detection checks for any harmful or offensive content in the output. Audit trail logging records the entire process for auditing purposes.
How the Salesforce platform works
The Salesforce platform abstracts the complexity of large language models. It helps you get started with LLMs today and establish a solid foundation for the future. The Salesforce platform powers the next generation of Salesforce CRM applications (Sales, Service, Marketing, and Commerce), and provides you with the tools you need to easily build your own LLM-powered applications. Although Salesforce is architected to support the different strategies mentioned earlier (train your own model, customize an open-source model, or use an existing model through APIs), it is configured by default to use the “use existing models through APIs” strategy, which lets you unlock the power of LLMs today and provides you with the fastest path to AI innovation.
The Salesforce Platform combination of Prompt Builder and the Einstein Trust Layer lets you take advantage of LLMs without having to train your own model:
- Prompt Builder lets you ground prompts in your company data without training a model on that data.
- The Einstein Trust Layer enables you to make API calls to LLMs without compromising that company data.
| Computational Resources | ML and NLP engineers | Relevant outputs | Time to innovation | |
| Train your own model | Highest | Yes | Highest | Slowest. Training a model can take months |
| Customize an open-source model | Medium | Yes | Medium | Medium. Can also take months |
| Use an existing model through APIs | Lowest | No | Lowest | Fastest. Start immediately with API calls |
| Use an existing model through APIs with in-context learning powered by Prompt Builder and the Einstein Trust Layer | Lowest | No | High | Fastest. Start immediately with API calls |
Get started with an LLM today
The Salesforce platform gives you the tools you need to easily build your own LLM-powered applications. Work with your own model, customize an open-source model, or use an existing model through APIs.


























