




What’s one thing that AI is lifting up even higher than workplace productivity? Customer expectations. Today, 90% of consumers expect an instant response when they reach out for service requests, while 82% say they’re more loyal to brands with authentic personalization. It’s not hard to connect the dots: AI has made it easier than ever to create authentic, bespoke interactions at scale — cementing real-time “hyper-personalization” as the new status quo for customer engagement.
But like most tech revolutions, this CX renaissance isn’t evenly distributed… yet. While text-based AI customer service agents are becoming ubiquitous, most voice channels still rely on legacy IVR chatbots and other outdated systems. With an estimated 80% of inbound customer interactions still coming through voice, this presents a glaring gap for most companies.
So, what gives? If voice is such a valuable channel, why aren’t brands rushing to deploy AI there? The simple answer is, building AI voice agents is hard. From latency, to the inherent messiness of verbal conversation, to the mechanics of agent-to-human handoffs, delivering a great voice experience can be more challenging than it seems. To set your organization up for success, it’s essential to start with the right architecture.
When 600 milliseconds is an eternity
Imagine talking to a friend who pauses for a second or two in between every response. No words, no body language, just awkward silence. It wouldn’t take you very long to suspect something might be wrong with your friend. In fact, humans are so attuned to the natural rhythm of spoken language that most of us insert filler words like “umm” and “like” to make conversations feel more fluid.
Of course, AI agents aren’t human, and accurately simulating the way we speak in real life presents numerous technical challenges. For one, LLMs are too large and slow to classify user intent and return a response without noticeable lag. Many ASR (automatic speech recognition) models also rely on pauses to figure out if a user has finished speaking rather than semantically understanding when a statement is over. This can add 500-600 milliseconds of latency per turn, which may not seem like a lot, but is more than enough to frustrate users.
How it works in Agentforce: To power Agentforce Voice, we fine-tuned a specialized small language model (SLM) designed to classify topics as quickly as possible, vastly reducing response time. And thanks to new parallelization, Agentforce doesn’t have to wait for topic classification to finish to kick off information retrieval — that context is already being pulled while the topic is identified. Direct integration with Data Cloud for RAG further expedites knowledge lookups by returning raw chunks that are contextually relevant rather than summaries, reducing latency from multiple seconds to about half a second.
TTS caching is another powerful optimization we’re rolling out to avoid having agents regenerate the same string of text. Generated speech is now cached, so when an agent needs to repeat the same string, it can simply reuse the last one, cutting down the time needed to output an audio response. Semantic endpointing is another SLM-powered feature we’re adding to detect when a user is finished speaking, eliminating the need to wait for a fixed-duration pause. And remember those “umms” and “likes?” For situations where a little latency is unavoidable, we’re introducing filler noise and other audio indicators to let users know the agent is still working on their task.
Pointless point solutions
If all those latency optimizations didn’t hammer the point home, integration is a crucial aspect to standing up a successful AI voice agent. But latency is just the beginning. Without tight integration with your company’s existing tech stack, your voice agent won’t be able to stitch together a complete transcript when calls are forwarded from another number, such as an existing IVR system. This prevents the agent from getting the context it needs to quickly and accurately identify the right topics and actions.
That same lack of context makes it virtually impossible to escalate calls to a human agent without forcing the customer to repeat everything they just said to your AI agent. And without a complete transcript, you’ll also lose the ability to perform any in-depth analysis such as sentiment detection. Even something as fundamental as two-factor authentication will be difficult to bolt onto a siloed AI voice agent.
How it works in Agentforce: Agentforce Voice will offer first-class integration with Salesforce Voice, allowing your agent to seamlessly connect to partner telephony via PSTN or, in the future, SIP, as well as major CCaaS platforms. Customers can configure existing IVR flows to forward calls to a special Agentforce phone number, ensuring that Service Cloud captures end-to-end conversational context. This isn’t just invaluable analytics data to drive evaluations, session tracing and debugging — it’s also what gives human agents the visibility they need to seamlessly take over an escalation. When a customer calls in, Agentforce immediately begins a live transcript that can be monitored in real-time directly through Service Console. Human agents can jump in at any point, or automated escalation triggers can be configured for situations like refund requests.
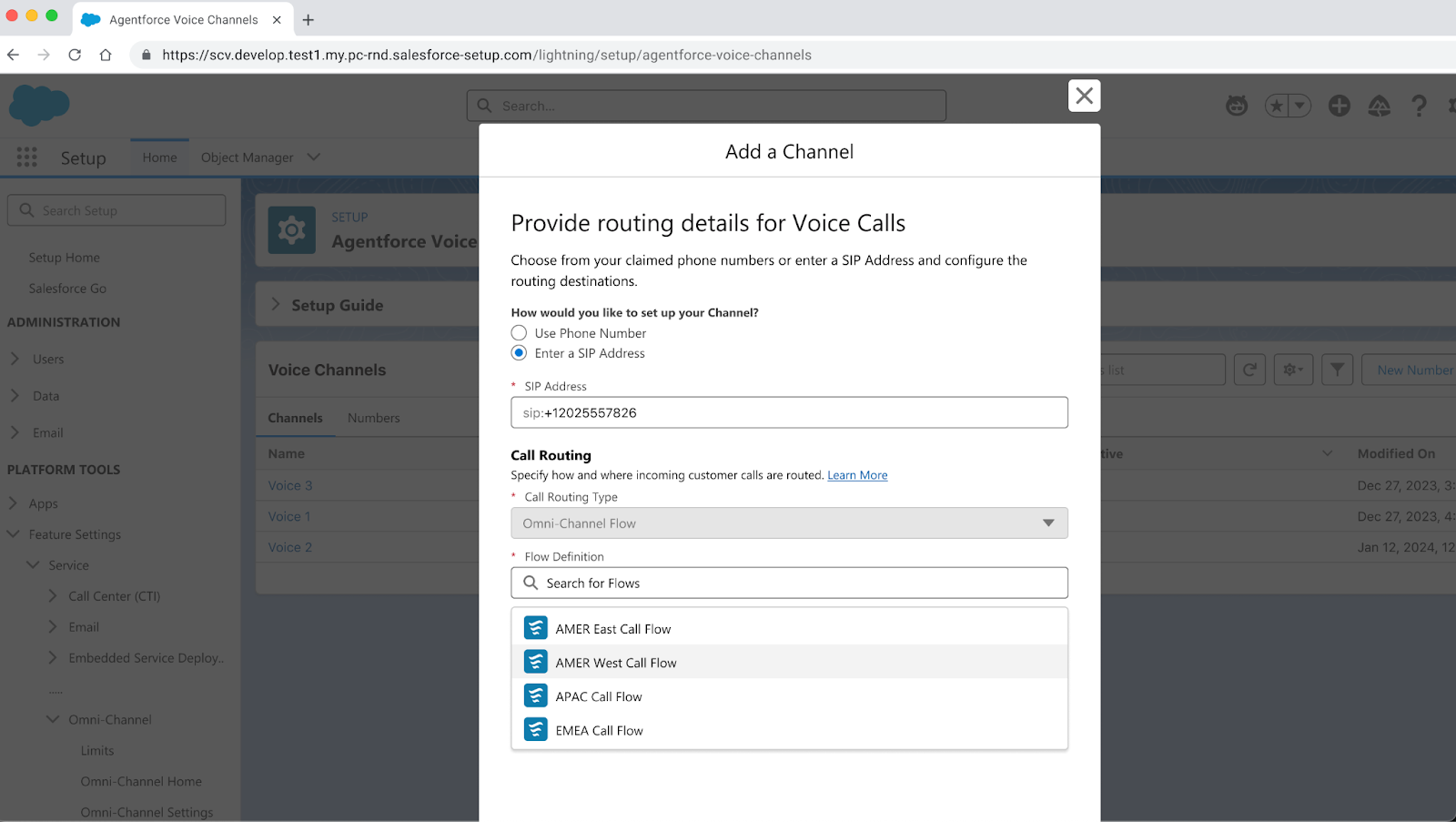
What makes this all possible is a new WebSocket protocol that allows your voice agent to constantly be listening, replacing the turn-based HTTP requests used by text-based agents. WebSockets establish a persistent connection to Agentforce’s Atlas Reasoning Engine, allowing messages to flow as they come in and go out as they’re generated by the agent. That persistence not only ensures a rich data pipeline, but also powers numerous quality-of-life optimizations that we’ll cover in the next section.
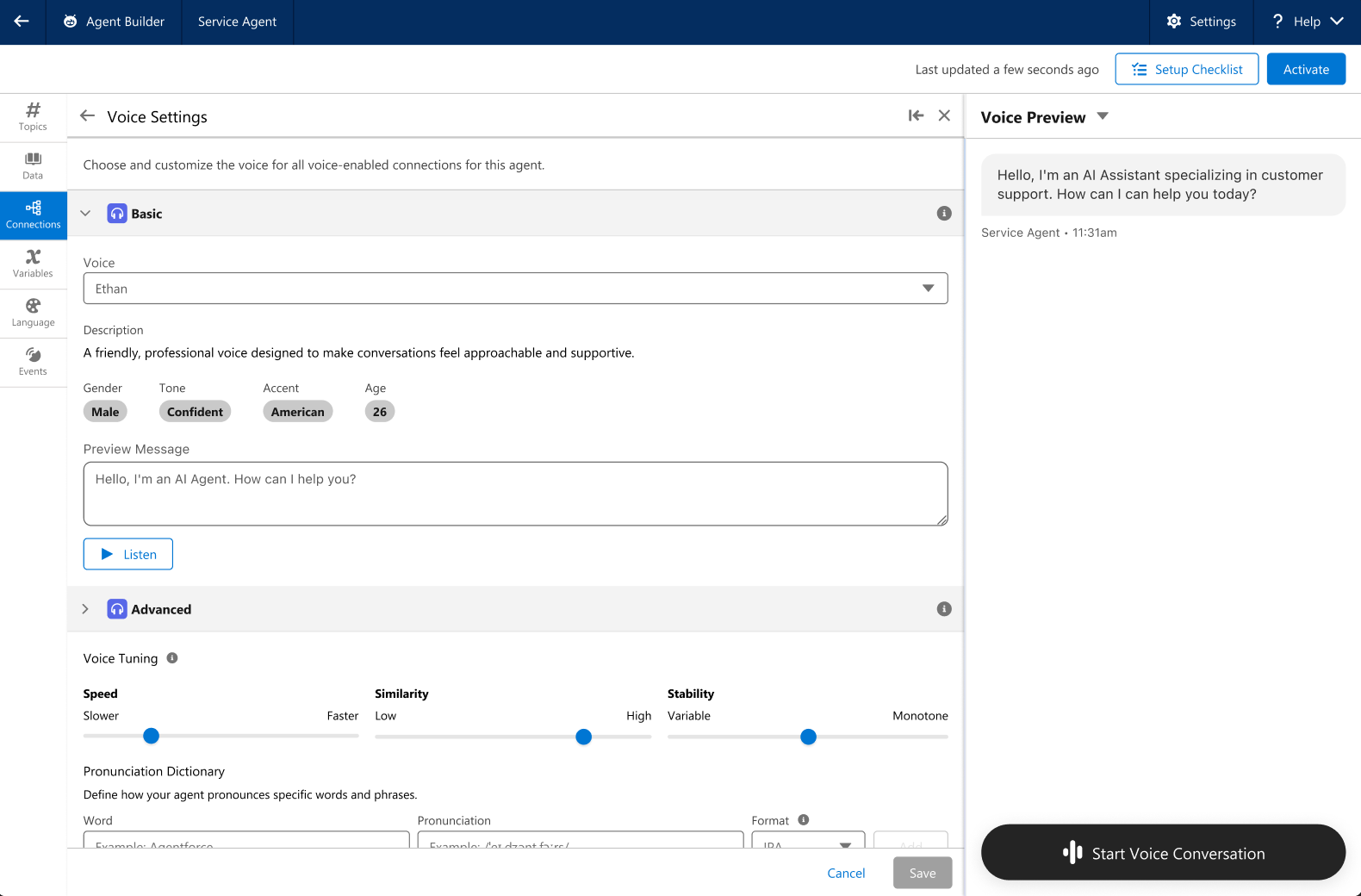
Best of all? Agentforce Voice can reuse all your existing text-based agent configurations, including action and context variables, eliminating the need to build from scratch. You can enable voice for any existing agent and make tweaks in the same builder experience you’re already familiar with. Once voice mode is enabled, you can customize settings like the agent’s gender, tone and accent, as well as advanced controls that define how fast your agent speaks, their emotional range and how consistently they stick to the underlying voice model and original audio used to train that specific voice selection.
Talking over ourselves
In more ways than not, the way we speak in everyday life is messier than the way we write. Our most mispelled, grammatically flawed, emoji-laden texts are still easier for machines to parse than people talking over each other or veering off in new directions midthought. We tend to not only interrupt the person (or AI agent) we’re talking to, but we frequently interrupt ourselves, whether it’s asking too many questions in a row or simply blanking for a moment and biding time with a few “umms.”
While humans can navigate these linguistic quirks intuitively, an AI agent takes nothing for granted. Every time a customer says something like, “yeah, uh-huh,” the agent has to figure out (almost instantly) if it’s a genuine interruption that needs to be addressed, or if it’s simply the customer acknowledging them. Whenever a customer asks multiple questions in a row without waiting for a response, the agent not only has to decide what order to respond in, but also store the context of the previous queries so it can answer later.
How it works in Agentforce: Remember those handy WebSockets? Well, it turns out they’re useful for way more than just listening for potential case escalations. If a customer starts asking a new question while an agent is in the middle of a response, Agentforce is able to dynamically shift gears and answer the most recent question while continuing to work on the previous one in the background — turning multiple queries into subtasks and synthesizing a comprehensive final response. In contrast, an HTTP text-based agent will grey out the input box while it’s generating an answer. WebSockets allow us to sidestep that limitation.
But how does Agentforce tell the difference between an interruption and an acknowledgement or filler? Since agents can’t rely on intuition, we implemented a specialized LLM-as-a-judge, as well as a “short-circuit” that forces the agent to stop speaking immediately. If the LLM determines that there’s a genuine interruption, the short-circuit kicks in to prevent the agent from talking over the user. If it’s just filler words, the agent will carry on with its response.
Last but not least, we’re rolling out new tools for entity confirmation and pronunciation. When a user provides their name or email address or credit card number, Agentforce identifies those as special fields and reads them back to the customer to confirm spelling.
And a new pronunciation dictionary allows organizations to manually define the way agents pronounce specific words.
Together, these new tools and features will help power a new era of AI-first CX, enabling companies to deliver high-quality, hyper-personalized voice interactions at scale. We’re excited to roll out these and many other innovations at Dreamforce 2025.








