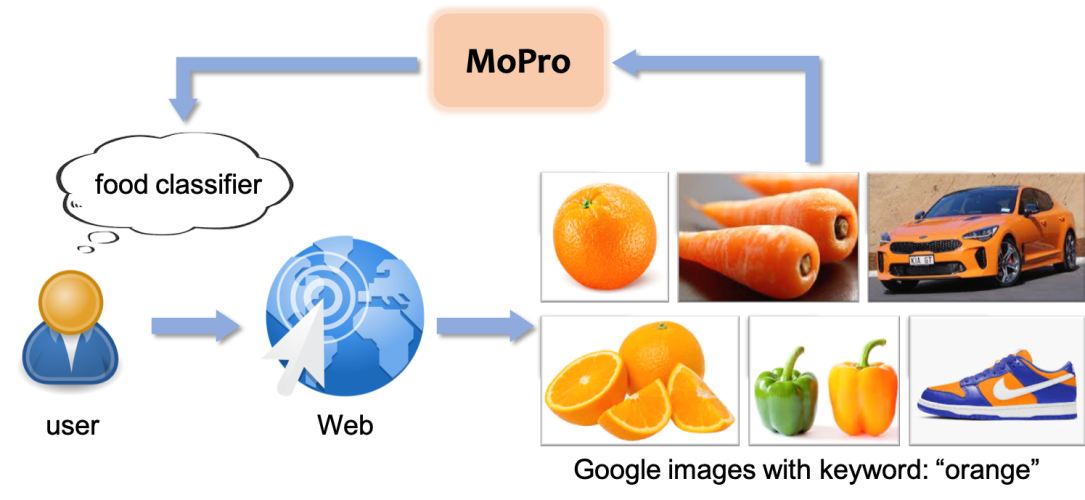

TL; DR: We propose a new webly-supervised learning method which achieves state-of-the-art representation learning performance by training on large amounts of freely available noisy web images. Deep neural networks are known to be…




Our Salesforce Research team is inviting submissions from university faculty, non-profit organizations, and NGOs to apply for our Salesforce AI Research Grant.


The 58th Association for Computational Linguistics (ACL) Conference kicked off this week and runs from Sunday, Jul 5 to Friday, Jul 10 in a fully virtual format. ACL is the premier conference of…


