Architectural Lessons: The Salesforce Customer Zero Implementation of Data 360



Explore how enterprise data architecture comes to life through the Salesforce Customer Zero implementation of Data 360.

Architects face a growing responsibility to design enterprise data architecture that supports trusted, scalable data exchange across increasinly complex environments.
The challenge goes beyond system integration. It is about building a foundation where data can move securely and consistently across clouds, platforms, and business units, with shared meaning, unified identities, and policy-governed activation across every channel.
This is the story of how Salesforce built that foundation internally through its Customer Zero implementation of Data 360. It provides a real-world reference for designing governed, interoperable data architectures that enable zero copy data access, unified semantics, and AI-ready intelligence across CRM, analytics, and Agentforce.
The architect’s responsibility with Data 360
Designing with Data 360 requires architects to think beyond point-to-point integrations. Modern enterprise data architecture requires data that is trustworthy, meaningful, governed, reusable, and AI-ready across every cloud, org, and platform. Most organizations now operate in hybrid, multi-org, multi-cloud environments that blend Salesforce, external platforms, on-premises systems, and a wide range of APIs.
In this environment, architectural decisions carry long-term consequences. Each integration choice directly influences:
- Data governance: Maintaining consistent policy, lineage, semantics, and access controls across systems
- Latency and performance: Delivering the freshness and scale required for real-time activation and analytics
- Operational efficiency: Minimizing custom code, reducing pipeline maintenance, and preventing integration sprawl
- AI readiness: Enabling unified identities, complete data context, and high-quality inputs for reasoning-rich AI systems like Agentforce
- Cost and sustainability: Reducing duplication, unnecessary movement, and compute-heavy transformations
The Customer Zero implementation of Data 360 provides a valuable model for architects navigating these trade-offs. It shows how a governed, interoperable, zero copy–enabled data fabric operates at enterprise scale and supports long-term growth and innovation.
The multi-layer enterprise data architecture
In the Data 360 implementation, our multi-layer enterprise data architecture demonstrates how an AI-ready enterprise operates as an integrated system. It brings together data sources, external platforms, unification and intelligence, and application experiences into a cohesive, governed architecture.
The architecture diagram below provides a high-level view of how enterprise data architecture functions as a connected system. It illustrates how data flows, how the system embeds governance, and how Data 360 intelligence powers Agentforce at scale. Each layer plays a distinct role while working together to support trusted data movement, interoperability, and enterprise-wide activation.
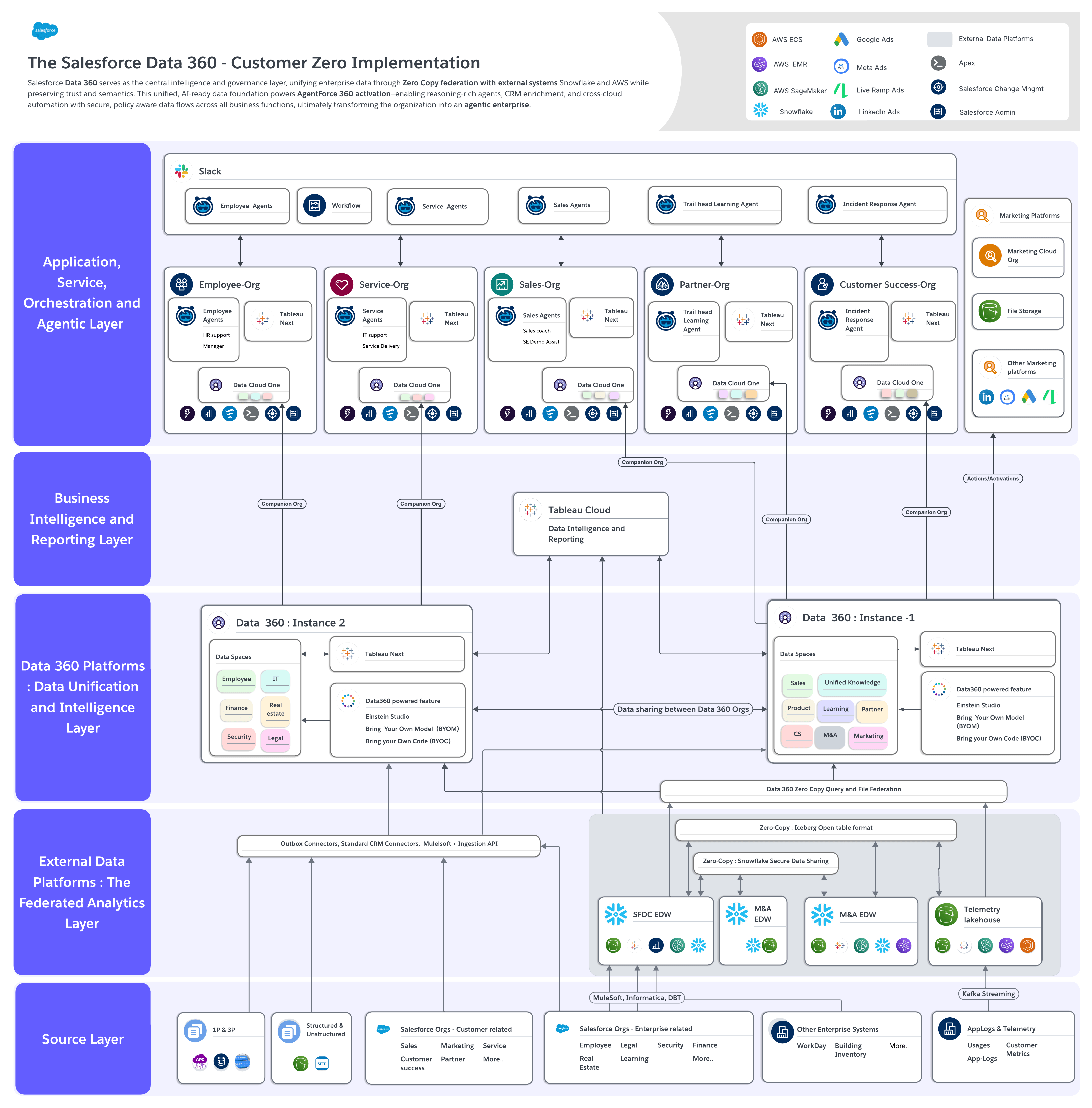
The following sections break down each layer of the Customer Zero Data 360 implementation architecture.
1. Source Layer: Supplying enterprise data at scale
This layer represents the broadest and most diverse part of the enterprise data ecosystem.
The Source Layer aggregates data from more than 50 systems, including cloud-based platforms, on-premises environments, and third-party applications. It provides the raw, multi-domain input that fuels unification, activation, and intelligence across the enterprise.
Key components of the Source Layer include:
- A highly diverse system landscape: More than 50 data sources across the enterprise reflect both first-party operational systems and specialized third-party applications. This ecosystem processes a complex mix of structured, semi-structured, and unstructured data, requiring flexible ingestion patterns, strong governance, and semantic alignment to ensure downstream consistency.
- Salesforce-first operational backbone: A significant portion of core business data, including Sales, Service, Marketing, Support, IT services, and knowledge repositories, originates on the Salesforce Platform. This provides rich metadata, consistent schemas, and native integration points that accelerate Data 360 harmonization.
- Workday for enterprise operations: Workday serves as the system of record for human resources and finance, supplying employee, organizational, and financial datasets that participate in cross-domain use cases, such as workforce analytics, case routing, enterprise performance insights, and compliance reporting.
- Application logs, telemetry, and behavioral signals: High-volume, high-velocity application logs, performance metrics, and telemetry streams are continuously collected from global deployments. These signals provide essential context for operational analytics, observability, customer behavior modeling, and AI-driven reasoning.
Together, these sources create a broad, heterogeneous, and continuously evolving data supply.
The Source Layer enables Data 360 to apply identity resolution, harmonization, zero-copy interoperability, and AI-driven enrichment. These processes transform raw data into connected, trusted, actionable intelligence across the enterprise.
2. Federated Analytics Layer: Processing and analyzing external data
The multi-layer enterprise data architecture integrates a robust ecosystem of external data platforms to support large-scale analytics, advanced processing, and governed data exchange. Together, these platforms extend enterprise compute and analytical capacity while staying integrated with Data 360, ensuring consistent governance, aligned metadata, and seamless interoperability.
The Federated Analytics layer represents a major operational unlock by eliminating redundant data pipelines while maintaining performance, security, and compliance. To navigate these options, the Data 360 Interoperability Decision Guide provides guidance on when to adopt zero-copy access versus traditional data integration patterns.
Key components of the Federated Analytics Layer include:
- Snowflake: Serves as the enterprise data warehouse and analytics engine, including data from mergers and acquisitions. Shared datasets are stored in Apache Iceberg open table formats, enabling zero-copy interoperability with Data 360 for governed, no-movement data access.
- AWS S3 lakehouse with Trino and EMR Spark: Powers ingestion and processing of global application logs, telemetry, and large semi-structured datasets, supporting scalable analytics and compute-intensive workloads.
- MuleSoft and Informatica: Manages data ingestion, movement, ETL and ELT processes, transformations, and data quality across systems, enabling reliable, governed data pipelines.
- Tableau Cloud and CRM Analytics: Delivers enterprise business intelligence, visualization, and AI-assisted insights across data platforms using governed datasets.
- Airflow: Orchestrates pipelines and workflows across platforms to ensure reliable and repeatable data operations.
- Polaris and Apache Iceberg REST catalogs: Standardizes metadata management, lineage tracking, schema governance, and data quality across all data assets through integration with the internal enterprise catalog and Informatica.
Together, these platforms form a scalable and governed analytical backbone.
By interoperating with Data 360 through zero copy and shared metadata standards, this layer enables enterprise-scale analytics and processing without duplicating data or fragmenting governance.
3. Unification and Intelligence Layer: Governing and activating data with Data 360
Data 360 functions as the intelligence core of the multi-layer enterprise data architecture, unifying data from every system, cloud, and business domain to interpret, govern, and activate it consistently across the enterprise. It transforms raw data into shared meaning, enforces policies, and makes intelligence operational across the enterprise.
In the Salesforce Customer Zero implementation, Data 360 is provisioned as two strategic instances, aligned with recommendations from the Data 360 Provisioning Decision Guide:
- A customer-focused Data 360 instance: Powering customer intelligence, personalization, and activation
- An enterprise-focused Data 360 instance: Unifying operational, analytical, and cross-domain data
Together, these instances form the backbone for delivering trusted, connected, and AI-ready data at enterprise scale.
How the Data 360 Platform works
Data 360 brings together ingestion, semantics, analytics, artificial intelligence, and governance into a single, governed system. Within this layer, several tightly integrated capabilities work together to move data from ingestion through unification and activation.
Core responsibilities of the Data 360 Platform include:
- Unified and governed ingestion: Ingests data from dozens of systems using out-of-the-box connectors, ingestion APIs, MuleSoft integrations, and governed pipelines. Preprocessing, validation, and quality rules are applied before data lands, with batch and stream transforms supporting both high-volume and real-time processing. These ingestion patterns form the bronze layer of the medallion architecture.
- Domain intelligence through data spaces: Organizes data into domain-specific Data Spaces, such as Sales, Service, Marketing, and Support, ensuring consistent semantics, lineage, policy tags, and AI-ready context. This domain alignment enables reasoning across business areas and functions as the silver and gold layers of the medallion architecture.
- Zero copy interoperability with external platforms: Provides direct, governed access to external data platforms, such as Snowflake and AWS S3 lakehouse environments, using a zero copy architecture. This approach eliminates physical data movement, duplication, and reconciliation jobs while preserving performance and compliance.
- Analytics and AI reasoning on governed data: Converts unstructured data into search indexes and vector embeddings that serve as the reasoning substrate for Agentforce. At the same time, it enables enterprise analytics, augmented insights, and natural-language exploration through Tableau Cloud and Tableau Next running on governed Data 360 assets.
- Extensibility and enterprise AI capabilities: Enables custom code execution, model operationalization, and AI development through Bring Your Own Compute, Bring Your Own Model, and Einstein Studio. These capabilities allow teams to extend Data 360 while maintaining consistent governance and trust.
- Cross-org intelligence and governance built in: Supports secure, policy-aware data sharing across Salesforce orgs and Data 360 instances through Data Cloud One. Role-based and attribute-based access controls, lineage, semantics, and consent enforcement are applied consistently across all activation paths.
By unifying ingestion, semantics, analytics, and artificial intelligence under a single governance model, Data 360 enables enterprises to scale interoperability, reduce duplication, and deliver AI-ready data across the platform.
It is the architectural layer that turns distributed data into a trusted, operational system.
A Real-World Agentforce Lens on the Well-Architected Framework Pillars
Lessons learned from building a multi-org agentic ecosystem for the 10,000-person Salesforce Professional Services organization.



4. Business Intelligence and Reporting Layer: Delivering trusted insight with Tableau
In this layer, the architecture transforms governed enterprise data into trusted, consumable insight for human decision-makers and data analysts.
Tableau Cloud and Tableau Next anchor the Business Intelligence and Reporting Layer. In turn, this layer delivers a unified analytics experience built directly on governed, zero-copy–enabled Data 360 assets rather than downstream reporting extracts.
Architecturally, this ensures that executives, analysts, and operational teams interact with the same shared semantics, policies, identities, and metrics. These shared elements are the same ones that power automation and AI. By eliminating BI-specific data copies and shadow logic, analytics remain aligned with Agentforce reasoning and application execution. This reinforces a single, trusted source of truth across decision-making and operational workflows.
Key characteristics of the Business Intelligence and Reporting Layer include:
- Native analytics with Tableau Cloud and Tableau Next: Delivers enterprise reporting and analytics through Tableau Cloud and Tableau Next as a native capability of the Salesforce Customer Zero Data 360 architecture.
- Direct consumption of governed Data 360 assets: Enables analytics to operate directly on governed, Zero Copy–enabled Data 360 data, avoiding extracts, duplication, and BI-specific pipelines.
- Interoperability with external data platforms: Supports analytics across Snowflake and AWS lakehouse environments through seamless integration without data movement or duplication.
- Consistent enterprise metrics and semantics: Ensures dashboards, reports, and exploratory analytics are built on shared enterprise definitions for consistent interpretation across teams.
- AI-assisted and natural-language analytics: Provides natural-language exploration and AI-assisted insight generation through Tableau Next, grounded in Data 360 semantic models.
- Alignment with automation and execution: Keeps analytics aligned with Agentforce reasoning and application workflows through a shared, governed data foundation.
By operating as a native extension of enterprise data architecture rather than a downstream analytics silo, this layer ensures that insight remains trusted, consistent, and actionable. Beyond that, it connects governed data directly to human decision-making while staying aligned with Agentforce reasoning and application execution. The result is a single source of truth across analytics, AI, and operational workflows.
5. Application Experience Layer: Executing intelligence through Agentforce
The fifth layer executes the intelligence produced across Salesforce applications, Agentforce capabilities, and enterprise orchestration systems. It securely shares governed datasets across Salesforce orgs so that teams operate on consistent, trusted, and policy-governed data.
Within this layer, Salesforce applications surface data directly to power workflows, automation, personalization, and AI-driven experiences. Identity resolution, unified profiles, semantic models, and reasoning capabilities from Data 360 provide the necessary context. This enables Agentforce to act with relevance and confidence across channels.
At the application layer, multiple systems work together to operationalize intelligence:
- Salesforce applications and Agentforce personas: Agentforce builds and provision agents across multiple Salesforce orgs. It uses a unified data foundation to ensure consistent, context-aware interactions. These agents support our critical business functions, including:
- Sales & Enablement: Sales Coach, SE Demo Assist
- Employee Success: HR Support, Employee & Manager Concierge, Trailhead Learning
- Engineering & IT: Incident Response, IT Support, Service Delivery, Services Central Knowledge
- Flows, Apex, and orchestration: Salesforce Flow, Apex, and MuleSoft coordinate cross-cloud and system-to-system processes. This enables reliable and scalable execution across the enterprise.
- Slack as the engagement and action interface: Slack serves as the interface where users collaborate with agents, trigger workflows, and take action based on real-time insights.
- Activation to downstream channels: Data Actions activate governed data into downstream marketing and engagement platforms. This includes Salesforce Marketing Cloud, Meta, Google, and LinkedIn Ads, with policy and consent controls applied consistently.
Across the Application Experience Layer, unified metadata and ontology ensure data keeps a consistent meaning from reasoning through execution. The system enforces governance end to end, applying policy, consent, lineage, and access controls consistently to every dataset. These controls remain active as data moves through activation and consumption across applications and channels.
By executing governed intelligence directly within applications, agents, and orchestration systems, the Application Experience Layer turns insight into action. It is where enterprise data architecture delivers measurable outcomes through automation, personalization, and AI-driven execution.
What architects can learn from the Customer Zero implementation
The Customer Zero implementation of Data 360 provides a real, enterprise-scale reference architecture. It shows how Salesforce designs and operates a multi-cloud, multi-org, AI-ready data environment. This serves as a practical blueprint, not a product pitch, for implementing governed interoperability, semantic consistency, and zero-copy data access across heterogeneous platforms.
Architects study the Customer Zero implementation to see these architectural principles in practice and observe how Salesforce:
- Designs for multi-org scale: Standardizing identity resolution, semantic models, and governance while supporting federated operational autonomy
- Operates multiple Data 360 instances: Ensuring controlled data sharing through zero copy and consistent data contracts
- Implements open, table-format interoperability: Enabling unified metadata, schema alignment, and zero copy analytics across cloud data lakes
- Applies governance consistently: Enforcing access controls, lineage, consent, and policy inheritance across systems and platforms
- Reduces data movement for analytics and AI: Minimizing duplication and ETL complexity while keeping data in native environments
- Aligns semantic models across contexts: Ensuring transactional, analytical, and AI workloads operate on shared meaning
Together, these examples demonstrate how to design and apply enterprise data architecture across complex environments.
Put these architectural patterns into practice
As enterprises move toward AI-native data architectures, these patterns provide a clear path for turning architectural principles into operational systems.
Using Data 360, organizations can:
- Support multi-org enterprise environments through shared semantic layers, consistent identity resolution, and federated governance
- Unify internal and external data platforms while maintaining consistent governance, lineage, and schema controls
- Reduce data movement and operational overhead using Zero Copy and policy-based federation
- Deliver AI-ready data flows into CRM, analytics, Agentforce automation, and custom enterprise applications through governed operational patterns
- Maintain consistent reasoning and intelligence layers, so AI systems can act reliably across distributed environments
The Customer Zero implementation puts these patterns into action at enterprise scale. These real-world lessons provide a practical reference for designing governed, interoperable, multi-org, and multi-platform Data 360 architectures.
By applying these insights, you can build a scalable foundation that supports long-term AI adoption and transforms complex data into a powerful competitive advantage.
Discover what’s new for architects on the Salesforce Architecture Center