




In the world of AI agents that click, scroll, execute and automate — we’re moving fast from “just understand text” to “actually use software for you.” The new benchmark SCUBA tackles exactly that: how well can agents do real enterprise workflows inside the Salesforce platform?
What makes SCUBA stand out:

- It’s built around the actual workflows inside the Salesforce platform.
- It covers 300 task instances derived from real user interviews (platform admins, sales reps, and service agents).
- The tasks test not just “does the model answer the question” but “can the model use the UI, manipulate data, trigger workflows, troubleshoot issues.”
- It addresses a gap: current benchmarks often focus on web navigation and software manipulation — but enterprise-software “computer use” is hard to measure. SCUBA aims to fill that.
Key Takeaway: If you want agents that don’t just chat, but act in business software, this is a big step.
The Business Impact
Imagine an AI assistant that can navigate your CRM, update records, launch workflows, interpret dashboard failures, and help your service team get unstuck. That’s the vision this paper leans into.
Here’s why it’s compelling:
- Enterprise alignment: Many benchmarks are academic or consumer-web oriented. SCUBA puts the spotlight on business-critical environments (admin, sales, and service).
- Realistic tasks: By deriving tasks from user interviews and genuine personas, it bridges the gap between “toy benchmark” and “live user situation.”
- Measurable agent performance in context: It enables evaluation of how well an agent operates inside software systems, not just via text.
- Roadmap for future AI assistants: As more organizations adopt AI to automate software use (not just analysis), benchmarks like this set expectations, highlight challenges, and direct progress.
For businesses like Salesforce (and their customers) the implications are clear: better agent tooling, fewer manual clicks, faster issue resolution, more efficient sales/service teams. For the AI community: a new frontier of “task execution in UI” rather than “just text reasoning”.
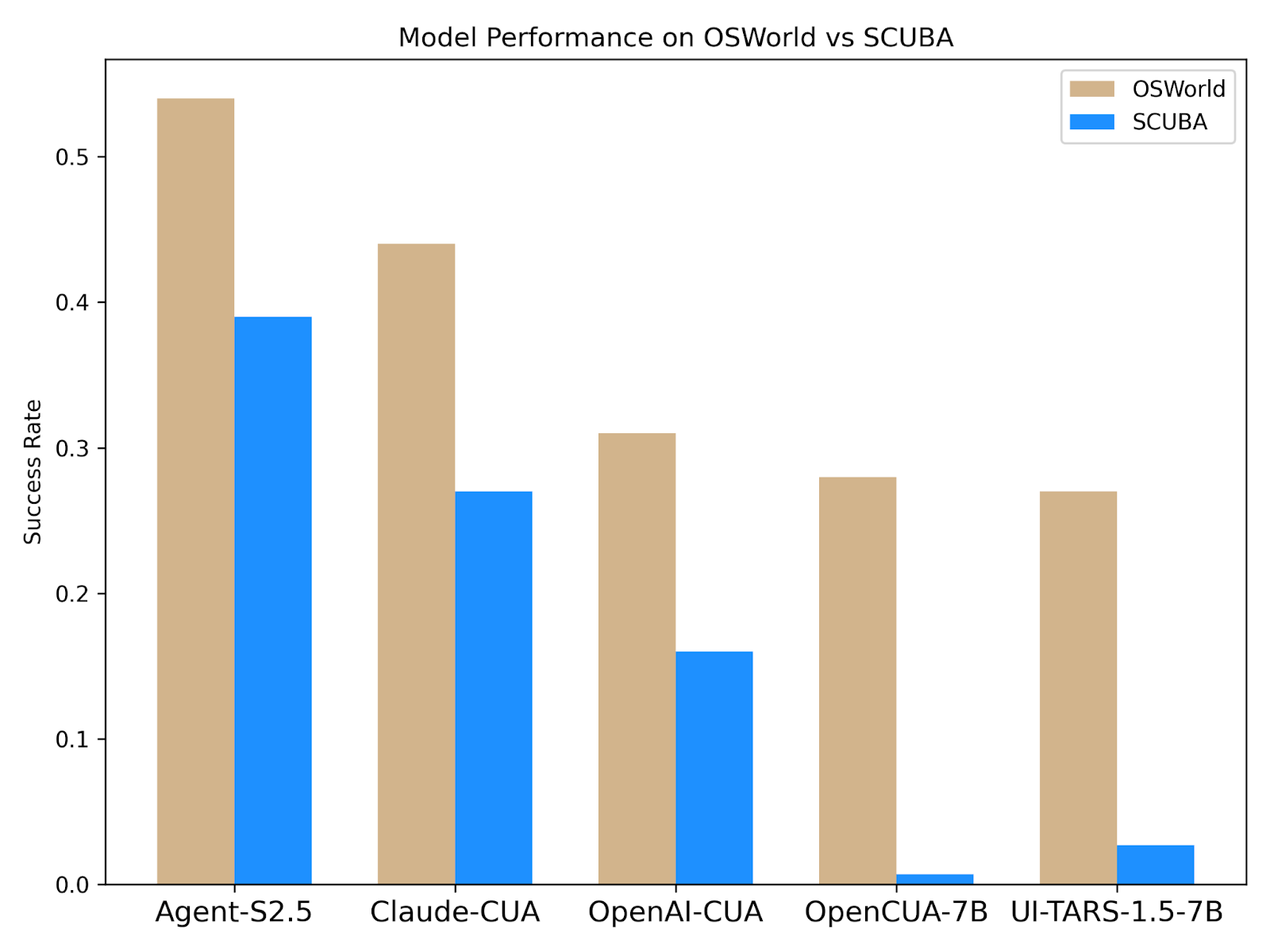
Key Insights:
1. Real-world domain shift is hard
The performance drop when moving from the more generic OSWorld benchmark (which covers desktop applications) to SCUBA (CRM, enterprise workflows) is significant. The experiment shows a chart of drop in success rates when shifting the benchmark.
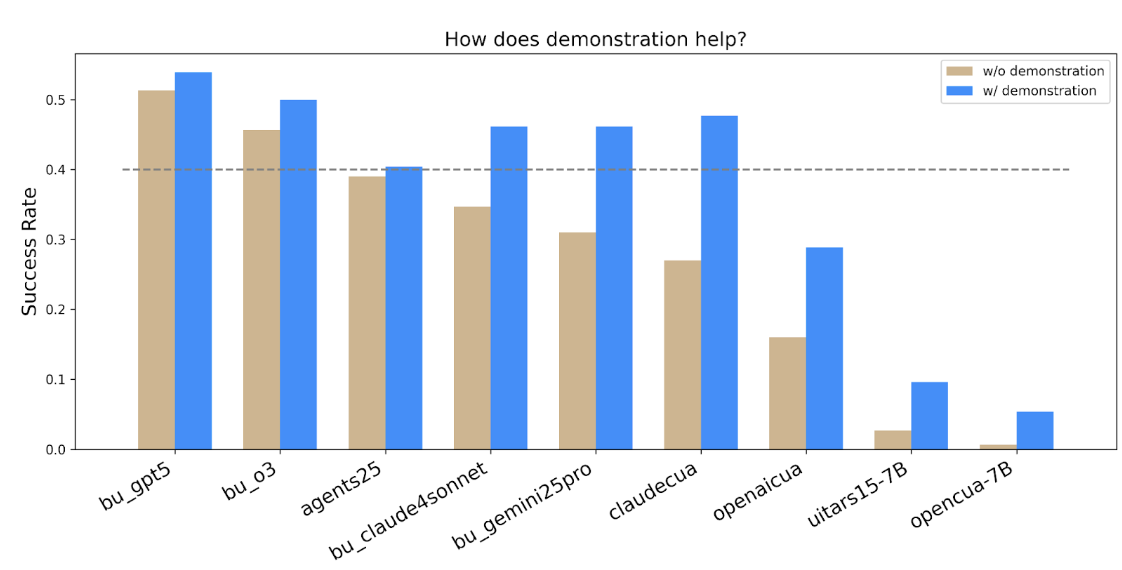
2. Demonstrations Help
Knowledge articles and tutorials on how to use salesforce platforms are easily accessible. One natural question is whether AI agents can leverage this information effectively like humans do. The experiment results reveal that
- Human demonstrations (showing the agent how to do a similar task) improved performance across most agents: higher success rates, lower time, lower token usage (please see the technical report for more details). But, some agents did not benefit as much.
- Also, some ended up using more steps in demonstration-augmented mode (for example due to discovering “shortcuts” that the human demo didn’t show). So the design of demonstrations still matters.
3. Cost, latency, and practical deployment matter
- Success rate is not the only metric; latency (time to complete tasks) and cost (API/token costs, number of steps) are also reported. For instance, browser-use agents had high success rates but higher latency (due to API service response time & multi-agent framework design).
- Demonstration augmentation not only improves success but can reduce time and costs (the paper reports ~13% lower time, ~16% lower cost in the demonstration-augmented setting).
- For enterprise adoption, this matters: an agent that succeeds but is too slow or too costly may be less useful in practice.
Implications for the Future of CRM Automation:
- Training data will shift toward UI/action context: Rather than only text datasets, we’ll see more benchmarks and datasets for “agent performed sequence in software” tasks (click → fill → submit).
- Enterprise software UX will matter for AI: As agents navigate interfaces, software products themselves may evolve to be more “agent-friendly” (e.g., more structured actions, better logs, agent-observable state).
- New kinds of robustness challenges: Agents will have to handle UI changes, versioning, error states, permissions — things that are less common in typical NLP benchmarks.
- Hybrid models and demonstration pipelines will become commonplace: As the experiments show, demonstrations help. Enterprises might build libraries of “how to” agent episodes for each workflow.
- Track more than success: Track latency, number of steps, cost (token/API), error recovery — these matter in practice.
Dive deeper into the research: SCUBA: Salesforce Computer Use Benchmark
Explore the benchmark: https://sfrcua.github.io/SCUBA/





















