




What Is Deep Research?
Deep Research ≠ Deep Search.
You may have come across “Deep Search” features in tools like ChatGPT or Claude — designed to enhance retrieval and concise answers. While Deep Search focuses on retrieval performance and short-form answers, Deep Research is about understanding, reasoning, and synthesis — combining adaptive planning, retrieval, analysis, and context engineering to produce long-form, well-cited research outputs.
Think of it as moving from “find me something” → “explain and reason through this topic for me.”
Unlike simple search tasks, Deep Research requires patience, iteration, and strategic depth — similar to how a human analyst or consultant would work.
Traditional AI search systems are built to answer quick factual questions:
“What’s Salesforce’s revenue in 2024?”
But Deep Research asks:
“How is Salesforce’s revenue growth correlated with generative AI adoption in the enterprise sector, and what can we learn from competitors’ go-to-market shifts?”
This shift changes everything — the time expectation, width of exploration, and depth of reasoning are far greater.
Deep Research blends planning, reasoning, and writing — not just retrieval.
Key building blocks include:
- Adaptive Planning: dynamically decomposing complex research goals
- Retrieval: gathering from diverse, multimodal sources
- Analysis & Reasoning: connecting dots across evidence
- Context Engineering: curating context for LLMs to stay consistent
(see this great piece) - Long-Form Synthesis: writing coherent, well-cited reports
What Is Enterprise Deep Research — and Why Does It Matter?
In an enterprise setting, research doesn’t live in isolation. Information is scattered across:
- Internal systems such as Salesforce, Slack, Google Docs, Calendars, internal knowledge bases, etc.
- External sources such as LinkedIn, GitHub, public news, reports, web data, etc.
Enterprise Deep Research bridges both worlds — combining internal knowledge and external insights to serve strategic business goals.
Example business applications include:
- Sales: Account research and competitive analysis
- Service: Emerging issue triage across support data and forums
- Marketing: Market trend synthesis from CRM and external media
- Leadership: Strategic decision briefs and forecasting
- Engineering: Benchmarking competitors’ tech stacks and repos
The outcome isn’t just answers — it’s insights that drive action.
Enterprise Deep Research reports are powerful tools that serve multiple purposes. They act like intelligent consultants—guiding every employee from individual contributors to senior executives in making better decisions.
These reports distill complex knowledge into accessible insights that can fuel real-time services, accelerate answer discovery, and uncover hidden patterns or root causes behind business challenges.
Unique Challenges in Enterprise Deep Research
- Planner Intelligence
- Does the system know where to search for what?
- Can it balance internal vs. external data sources?
- How does it manage time-sensitive, contradictory, or incomplete information?
- How does it coordinate across tools like Salesforce, Slack, Google Workspace, and LinkedIn?
- Tool and Data Access
- Are the right APIs and connectors in place?
- Can the system parse and retrieve data accurately from structured and unstructured sources?
- Privacy and Access Control
- Internal data isn’t open to everyone. Who is allowed to see what?
- How can the system respect permission hierarchies and data residency rules?
- Citation and Evaluation
- How do we ensure every insight is traceable to its source?
- How do we evaluate the quality of research when human expertise is uneven or fragmented?
- How do we detect duplicated or conflicting information across systems?
An Example of Enterprise Deep Research
In one of our internal use cases for sales, we designed a modular, multi-graph architecture that mirrors how human researchers operate, dividing and conquering through specialized sub-systems that collaborate intelligently.
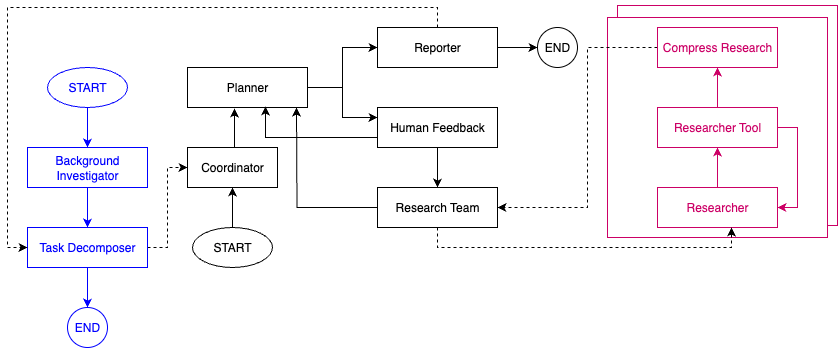
1. Planner Sub-Graph
The Planner is the brain of the system — decomposing high-level research goals into actionable subtasks.
- Task Input: Accepts natural language research requests (optionally paired with a predefined or LLM-generated template).
- Background Investigation:
The Background Investigator Agent scans multiple data layers:
- Public web (search, crawlers)
- Computational tools (code execution, analysis modules)
- Internal systems (Salesforce MCPs, CRM data connectors)
- Task Decomposition:
Using findings from the background stage, the planner breaks down the problem into well-defined subtasks mapped to suitable tools. - Subtask Execution:
Each subtask is dispatched to the Orchestrator Sub-Graph, either in parallel (for independent tasks) or sequentially.
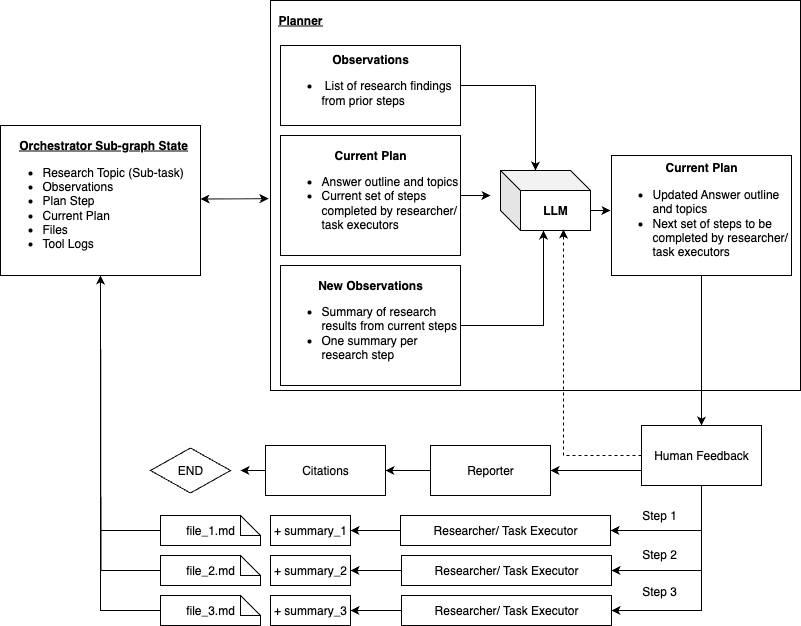
2. Orchestrator Sub-Graph
The Orchestrator is the project manager of Deep Research — overseeing each subtask and synthesizing partial findings into a unified report.
- Step 1: Creates a rough outline of the final report and assigns a set of N research steps to specialized Task Researcher/Executor Sub-graphs (e.g., Public Web Researcher, Internal Salesforce Researcher, Coder, etc.).
- Step 2+: Iteratively refines the outline by analyzing the outputs from executors, identifying missing pieces, and planning the next research wave.
- Reporting: Once coverage is sufficient, the Reporter Agent consolidates findings, generates a long-form report, and attaches citations.
- Human-in-the-loop: Optional human feedback can be integrated at any stage to refine direction or validate conclusions.
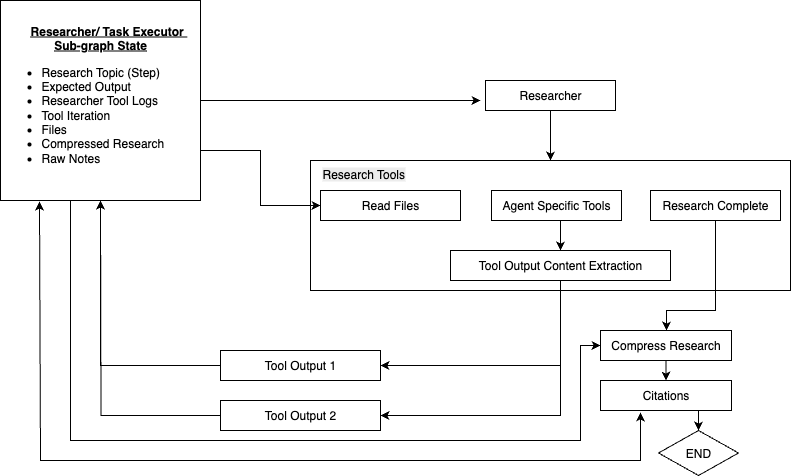
3. Task Researcher / Executor Sub-Graph
Each executor agent focuses on a single task — whether that’s querying Salesforce data, summarizing a GitHub repo, or running a code experiment.
They act as the hands of the system, executing with precision, feeding results back to the orchestrator for synthesis.
4. Tools
Our framework employs specialized tools designed to navigate distinct data landscapes. These tools act as the hands of the system, executing targeted queries to build a comprehensive view. The primary tools include:
- Web Search: This tool queries the public internet to gather external information, such as public news, market data, and competitor reports. This allows the system to incorporate a broad, external perspective into its analysis.
- Enterprise Knowledge Search: To tap into proprietary company intelligence, this tool searches internal knowledge bases like Trailhead, Highspot, and Confluence. It retrieves crucial information from onboarding documents, product details, and competitive battle cards, directly addressing the need to leverage internal data.
- CRM Search: This tool connects directly to internal systems like Salesforce to obtain account details and other customer relationship data such as opportunities and conversational data.
- Conversation Search: Internal Slack conversations from different channels and messages.
The Planner Sub-Graph intelligently coordinates these tools, determining whether to deploy them in parallel or sequentially based on the research task.
Enterprise Deep Research Evaluation
Having established the primary capabilities of these systems, it becomes necessary to assess Deep Research models using evaluation methods distinct from those applied to search or Q&A models.
In Deep Research, accuracy is necessary, but not sufficient. A system can be 100% correct on individual data points yet fail to produce a useful strategic analysis. Therefore, our evaluation must shift.
The ultimate goal is to measure how effectively an agent can understand a complex goal, reason across disparate sources, and synthesize information into a coherent and actionable report.
Why Does Benchmarking Matter?
Without structured evaluation, Deep Research remains anecdotal to users, where “it feels smarter” or “this report looks good.”
This isn’t enough for the enterprise. Business enterprise contexts demand repeatable, explainable, and quantitative benchmarks. This rigor is especially vital when multiple agents (OpenAI, Gemini, Slackbot, etc) are producing business-critical analyses.
Benchmarking Deep Research systems is not just about leaderboard scores. It’s about building trust. For any enterprise user to act on an AI-generated insight, they need clear answers to three fundamental questions:
- Traceability: Where an insight came from
- Transparency: How it was derived
- Consistency: Whether it aligns with corporate truth
Benchmark Practices in Pipeline
Our recent research: SFR-DeepResearch [1], DeepTrace [2], HERB [3], and LiveResearchBench [4], provide complementary perspectives on how to measure these capabilities:
- SFR-DeepResearch [1] (https://arxiv.org/abs/2509.06283) focuses on training autonomous single-agent researchers with an RL recipe that improves planning and tool use; it demonstrates capability gains on external reasoning benchmarks rather than proposing a new evaluation pipeline.
- DeepTRACE [2] (https://arxiv.org/abs/2509.04499) contributes an audit framework that measures traceability and factual support at the statement–citation level, turning known failure modes into eight measurable dimensions and revealing large fractions of unsupported claims across systems.
- HERB [3] (https://arxiv.org/pdf/2506.23139) benchmarks Deep Search over heterogeneous enterprise data (Slack, GitHub, meetings, docs), quantifying retrieval difficulty at scale (39k+ artifacts; answerable & unanswerable queries) and showing retrieval as a primary bottleneck for downstream reasoning.
- LiveResearchBench [4] (https://arxiv.org/pdf/2510.14240) is a benchmark of 100 expert-curated tasks spanning daily life, enterprise, and academia, each requiring extensive, dynamic, real-time web search and synthesis. As well as an evaluation suite covering both content- and report-level quality, including coverage, presentation, citation accuracy and association, consistency and depth of analysis.
Together, they motivate an enterprise evaluation that spans coverage/recall, citation accuracy & auditability, reasoning coherence, and readability, while keeping a clear boundary between Deep Search (finding the right evidence) and Deep Research (planning, reasoning, and long-form synthesis).
In our internal benchmarks, inspired by these frameworks, we propose on five core dimensions for enterprise evaluation:
| Dimension | What It Measures | Why It Matters |
| Coverage | How broadly and deeply the agent explores relevant information across sources | Ensures completeness; critical for strategic and competitive analyses |
| Citation Accuracy & Thoroughness | Whether insights are verifiably grounded in credible internal or external evidence | Builds trust and accountability in enterprise decisions |
| Reasoning Coherence | Logical consistency and clarity of multi-step reasoning | Reflects analytical depth; shows the model “thinks” like an analyst |
| Readability & Structure | Clarity, organization, and fluency of the final report | Makes outputs usable by business stakeholders and leadership |
| Internal Info Richness | How effectively the agent leverages proprietary internal enterprise data | Measures the system’s ability to combine internal truth with external insight |
Implementation and Results in Enterprise
To validate our evaluation framework, we benchmarked multiple systems on a diverse set of Enterprise Deep Research reports, which are long-form reports that combine Salesforce’s internal knowledge with external data.
Based on our enterprise use case of sales report generation and motivated by the above enterprise benchmark dimension, we select for dimensions that need evaluation for our pipeline: Report Readability & Structure, Internal Richness / Alignment, Citation Accuracy, and Coverage.
Our results below show that while readability is largely a solved challenge for most modern LLM agents, enterprise grounding and traceability clearly distinguish our Deep Research system. It not only generates fluent, well-structured reports but also anchors every insight to verifiable sources and Salesforce’s internal knowledge graph: a foundation for decision-grade trust in enterprise AI.
| Evaluation Dimension | Gemini | OpenAI | Salesforce |
| Citation Accuracy | 45.8% | 39.5% | 79.2% |
| Coverage | 3.28 / 5 | 2.98 / 5 | 4.0 / 5 |
| Internal Info Richness | 42.3 % | 30.2% | 73.7% |
| Readability & Structure | 3.6 / 5 | 3.6/5 | 3.6/5 |
*inaccessible org citations
*In this table, the numbers from Salesforce AIR are using OpenAI GPT-4.1-mini
With trust at the core of Salesforce’s values, we took an extra step to ensure our benchmark results were not only quantitative but also human-verified. To validate consistency, we conducted a parallel evaluation with expert human annotators and achieved a Fleiss’ κ (kappa) score of 0.6, indicating strong alignment between model judgments and human evaluations.
Cases like these highlight the next frontier of Enterprise Deep Research, where secure organizational data can be accessed, reasoned over, and synthesized to power diverse business use cases.
They also showcase the need for enterprise-oriented benchmarks and frameworks that measure not just accuracy or fluency, but the real-world impact and reliability of AI-driven research.
Conclusion
Enterprise Deep Research represents a significant leap beyond traditional search, transforming how businesses harness information. By integrating adaptive planning, diverse retrieval, sophisticated analysis, and long-form synthesis, it moves from simply answering “what” to deeply explaining “why” and “how.”
The unique challenges of enterprise settings—spanning internal and external data, access control, and robust citation—necessitate a specialized approach. Our multi-graph architecture, designed to mimic human research, addresses these complexities by orchestrating specialized agents and tools. Ultimately, the evaluation of such systems must transcend mere accuracy to focus on trust, traceability, transparency, and consistency.
Our internal benchmarks, validated by human experts, demonstrate that our Deep Research system excels in providing accurate, well-cited, and contextually rich insights from both proprietary and public data, setting a new standard for decision-grade AI in the enterprise.
Citation
Please cite this work as:
“`
Chien-Sheng Wu, Prafulla Kumar Choubey, Kung-Hsiang Huang, Jiaxin Zhang, Pranav Narayanan Venkit, “Towards Trustworthy Enterprise Deep Research”, Salesforce AI Research, Oct 2025.
“`
Or use the BibTeX citation:
``
@article{wu2025sfrdeepresearch,
author = {Chien-Sheng Wu, Prafulla Kumar Choubey, Kung-Hsiang Huang, Jiaxin Zhang, Pranav Narayanan Venkit},
title = {Towards Trustworthy Enterprise Deep Research},
journal = {Salesforce AI Research: Blog},
year = {2025},
}
```






















